Recursive Self-Improvement isa Portfolio Optimization Problem
York Westenhaver·Massey Branscomb·Aidan Grant
AlphaFund
Abstract
Recursive self-improvement is usually framed as software rewriting itself. We propose a narrower, measurable formulation: a corporation recursively improves when realized economic gains finance the next cycle of better prediction and deployment. Quantitative trading instantiates this loop with unusual precision, since decisions, costs, outcomes, and reinvestment are all digitized. We introduce the Economic World Model (EWM), a forecasting and control object scored on future realized outcomes, and summarize the firm’s standing as t-RSI, a standardized gap between alpha-creation and alpha-decay rates. We present evidence of the first general economic scaling law beyond language data; further evidence from live trading and held-out backtests support the framework. We position today’s firm as the present-moment derivative of a trajectory toward an Autonomous Self-improving Corporation (ASIC), in which capital allocation is itself executed by the firm’s software. Thus, recursive self-improvement can be reframed as an auditable capital-allocation process.
Introduction
The literature on recursive self-improvement spans decades, from Yudkowsky’s seed AI framing [1], through Schmidhuber’s Gödel Machines [2], to formal and empirical treatments of recursive self-improvement and intelligence explosion dynamics [3, 4, 5], to more skeptical analyses emphasizing diminishing returns and bottlenecks [6]. These formalisms differ in mechanism, but they share a simplifying assumption: the economic costs of the improvement step do not threaten the system’s existence. In reality, every FLOP and bit of data costs money [7, 8, 9]; self-improvement is an economic problem.
In the same way that biological organisms need resources and a suitable environment to survive and evolve [10, 11], the more complex system of the global economy needs capital to do the same [12]. A system that spends more on self-improvement than it earns from the resulting improvement slowly runs out of resources and dies. We thus define intelligence operationally: the capacity to acquire, preserve, and compound command over resources through accurate prediction. Because the environment is non-stationary and uncertain, the question shifts from whether RSI will occur to whether a system can generate sufficient capital to fund each attempt at self-improvement. This reframing casts recursive self-improvement (RSI) as a stochastic control problem under a survival constraint, with progress scored by the standardized signal-to-noise ratio of expected improvement against its posterior dispersion—a quantity we call t-RSI. For AlphaFund at the current operating point, the data-derived three-month t-RSI is 9.61 standardized units. It should be made clear that RSI is impossible to guarantee. The position and momentum of a particle can’t be known; a gamma-ray burst from across the universe could wipe all life out. We are proposing a concrete and measurable framework that allows researchers to talk about this hypothetical phenomenon in a grounded and empirical manner.
We develop this claim in five steps:
The Self-Improving Corporation. We formalize the corporation as stochastic optimal control under a balance-sheet survival constraint, specifying the state, transition law, objective, and capital-allocation program that convert predictions into a reinvestment process.
The Economic World Model. We decompose this theoretical problem into a practical prediction architecture and show that, under the channel coupling we make explicit, the decomposed system recovers the same first-order conditions as a joint-monolith optimum at the operating point.
The Portfolio Optimizer. We define the corporation’s controller as a model-predictive convex program over the EWM’s per-channel return forecasts, making heterogeneous interventions — a researcher hire, a data feed, a GPU, a position in AAPL — directly comparable.
The RSI Portfolio. We instantiate that controller channel by channel — investments, sensors, actuators, parameters, R&D — and present the empirical scaling and response laws that pin down each row of the marginal-return vector.
Trajectory. We study the long-run dynamics of the controller under those scaling laws—accounting for complementarity, filtration widening, and external capital—and argue that, if the preliminary laws hold under continued validation and marginal deployment keeps clearing after capacity, competition, financing, and market-impact costs, this process could plausibly capture a substantial share of financial-industry profits and serve as a bridge from quantitative trading toward broader priced economic action.
The Self-Improving Corporation
Corporations are intelligent self-improving systems. They can replace their own personnel, hardware, software, board, and even their business model and still retain their core identity—the legal name for this property is perpetual succession. Like the Ship of Theseus, what matters is not that any given component persists, but that the process that turns capital into improved capability and improved capability back into capital persists through continual reconfiguration. Most corporations do not, in fact, recursively improve; the question this paper asks is what conditions distinguish those that do. All for-profit corporations share the same objective: maximize shareholder value while remaining solvent [13, 14]. In service of that objective they observe their environment and internal state, allocate capital across operational capabilities, receive feedback in the form of earnings, and reinvest those earnings to augment future capability. We mean capital in the most generic sense: resources necessary to survive and improve. Dollars are generally fungible for those, and thus represent a satisfactory scalar approximation.
We model this sequential optimization process—the Corporate Loop—as constrained stochastic optimal control over the firm’s production cycle [15, 16, 17]. Quantitative trading is the cleanest case: its feedback loop is fast, direct, and dollar-denominated, and its production, sales, capital allocation, and reinvestment functions can all be specified precisely and measured at high frequency. The four subsections below set the four pieces the rest of the paper composes: the firm’s objective, the asset bundle the objective is computed over, the action vector that moves that bundle, and the coupled dynamics under which the bundle and the world evolve together.
Firm Objective and Accounting Identity
For-profit corporations exist to maximize shareholder value subject to remaining solvent [13, 14], and shareholder value is, by construction, shareholders’ equity—the residual claim on assets after liabilities are netted. The firm’s per-period reward is the realized log-return on that equity [18], the survival constraint is Kτ>0, and the cumulative objective Jt is the expected sum of those per-period rewards over a finite planning horizon. All later channels are priced against this Jt.
Definition 1Shareholders' equity
Shareholders’ equity at decision time t is the firm’s net worth: total assets minus total liabilities, marked to current dollars.
Kt=Assetst−Liabilitiest
Definition 2Per-period reward
The per-period reward at cycle τ is the realized log-return on shareholders’ equity from τ to τ+1. Log-returns track the Kelly time-average growth rate of a single surviving firm [18, 19]. The strict positivity Kτ>0 is the firm’s survival constraint: a trajectory in which equity hits zero is bankruptcy.
Rτ=log(KtKt+1)
Example
Suppose the firm has $100 of equity at time τ and $110 at time τ+1. Then Rτ=log(110/100)≈0.095—the firm earned $10 on $100 of equity over the cycle.
Definition 3Cumulative objective
The cumulative objective at decision time t is the expected sum of per-period rewards over a finite planning horizon T, taken under the firm’s policy G and its learned world model Wt, conditioned on the information available at t. It is a Discounted Cash Flow calculation over the foreseeable time horizon; how T is calibrated is discussed in the next section.
Jt=EG,Wt[τ=t∑T+t−1RτFt]
Example
Suppose at decision time t the firm has $100 in equity value of its assets and its world model forecasts those to rise to $110 over a one-cycle horizon (T=1). Then J1=E[log(Kt+1/Kt)]=log(110/100)≈0.095, or—in the dollar-equivalent form used throughout the rest of the paper—an expected $10 gain on $100 of equity.
The Corporation as a Bundle of Assets
To execute its optimization the corporation maintains an inventory of operational components—the channels through which it spends capital, generates the cash flows that keep it solvent, and earns capital back. Five channels suffice: what the firm holds (I, portfolio), what it can see (S, sensors), what it can do (U, actuators), how it learns (Z, R&D), and what it knows (Θ, parameters). We adopt a lossy five-channel partition that suffices for the quant-trading instance and that we will argue extends to the general case. The framework only requires that each row can be priced in dollars and that channel-specific scaling laws are estimable from the firm’s history.
The action vector at partitions the cycle-t change in the corporation into the same five channels as the state; each entry atk is the dollar change in channel k during the cycle (Action vector). The symbol-by-symbol definitions of the five channels are given via the projections in Corporation tuple and Action vector.
Definition 4Corporation tuple
The corporation is an abstract object. The state projection πstate partitions that object into the five channels that reflect the stock of capabilities that a corporation has at each decision time t:
Πstate(Ξt)=ItStUtΘtZt
Corporation tuple Ξt components.
Symbol
Channel
What it is
It
Portfolio
The vector of current resources that the corporation can sell to produce cash. In a trading firm this is tradable asset positions across equities, fixed income, commodities, currencies, derivatives, and other instruments.
St
Sensors
Data and feeds that bring information about both the firm and the outside world to light. For a trading firm this includes market data feeds, internal execution telemetry, satellite feeds, and social media data.
Ut
Actuators
Instruments the firm uses to modify the world. For a trading firm this includes the different assets it can trade, APIs it can call, types of financing it can access, AUM, margin, and equity.
Zt
R&D
How the firm processes new information and improves the other channels. For a quantitative trading firm, this determines the values for its parameters based on training data: the research process, experiment harnesses, and model selection infrastructure.
Θt
Parameters
Accumulated learned structure that represents the firm’s current beliefs about available transformations. For a quantitative trading firm, these are the parameters of the firm’s forecasting, execution, control, and value models.
Definition 5Action vector
The action vectorat partitions the cycle-t change in the corporation into the same five channels as the state. Each entry atk is the dollar change in channel k during the cycle:
Πact(at)=atIatSatUatΘatZ
Capital-allocation vector at components.
Symbol
Channel
What it is
atI
Investments
Net dollars rebalanced into (or out of) the trading book this cycle. The cleared trade, marked to current cash.
atS
Sensors
Cash spent acquiring data this cycle: new feeds, deeper archives, finer-grained subscriptions.
atU
Actuators
Cash spent extending the firm’s execution surface: new venues, routes, APIs, financing capacity.
atZ
R&D
Cash spent on researcher labor and capital-substitutable research: agents, GPU-hours, search infrastructure, sealed-holdout tooling.
atΘ
Parameters
Cash spent on training compute that produces the next set of model weights.
Coupled Dynamics
The environment Et is the part of the world outside the corporation that matters for the next cycle: prices, order flow, liquidity, counterparties, macro state, regulation, and the news process. Coupled dynamics states how the corporation and that environment move together after the firm acts.
Definition 6True corporate transition
The true joint transition lawW governs how the firm’s state Ξt and the environment Et co-evolve under an action at. It is a property of the world, not a model the firm has access to; the firm must approximate W with a learned Wt (Economic World Model).
(Ξt+1,Et+1)=W(⋅∣Ξt,Et,at)
Example
The world turns. The clock ticks, prices update. The corporation’s sensors measure these changes.
The small-firm approximation is the regime in which the environment’s next-cycle state Et+1 depends only weakly on the firm’s action at:
∂at∂Et+1≈0.
Suppose George Soros, in September 1992, shorts £10B against the Bank of England’s peg. The trade itself drains the Bank’s reserves; the next trade drains them faster; the pound’s market price collapses, and Soros makes a fortune [20]. When you are large enough to affect the market, the small-firm approximation no longer applies.
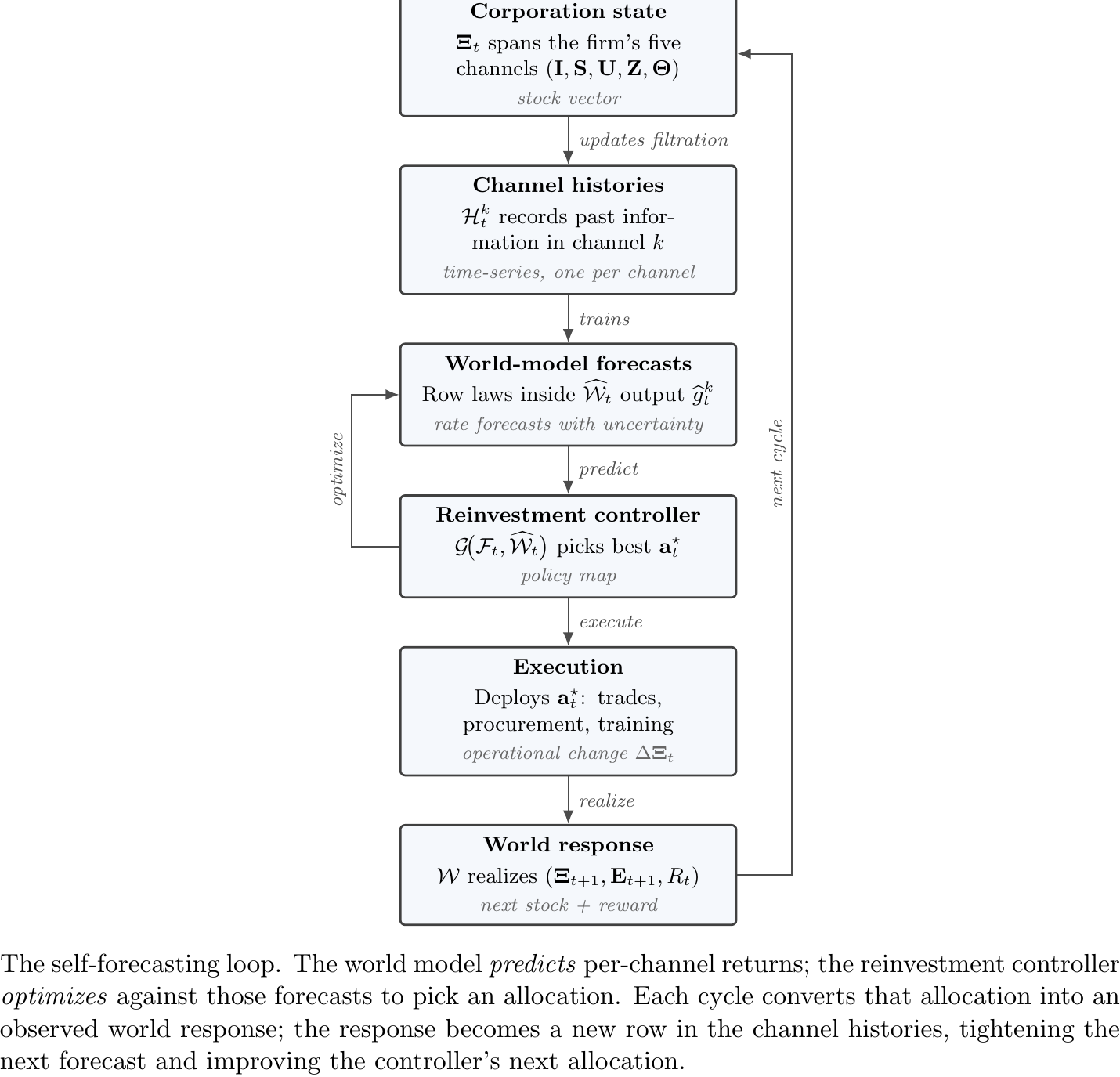
The Self-Forecasting Loop
Figure 1. The self-forecasting loop. The world model predicts
Every operating cycle appends one row of observations to each channel history Htk. The sensor channel can additionally widen by adding new data: Wayback Machine snapshots, exchange filings, alternative-data archives. Each turn provides the next iteration of training data.
Once enough rows accumulate, accurate predictions can be made on a channel-by-channel basis, allowing the firm to predict its own self-improvement dynamics. In theory, a unified world model would be trainable with enough data such that the firm could jointly predict its own state, improvements to it, and the state of the external economy all at the same time.
Concretely: at decision time t the controller queries the world model for gt off the trained row laws (predict), solves the convex inner program of Portfolio Optimization to pick the best action (optimize), executes the chosen at⋆, and the realized (Ξt+1,Et+1,Rt) becomes the new training row that tightens the next cycle’s forecasts.
Each improvement attempt teaches the firm something about itself. The action it took, the internal change it produced, and the reward that followed become a new row in the channel histories. As those rows accumulate, the firm gets sharper predictions about which future improvements will work and tighter confidence intervals around the value of its own next actions. The loop is the thesis of the paper compressed into one diagram; everything that follows is one of these arrows worked out in detail.
The Economic World Model
The previous section gave the firm a state, a coupled dynamics W, and a constrained optimization problem over a planning horizon. What it did not give the firm is a way to evaluate candidate allocations: given that the controller takes action at now, what does the next (Ξt+1,Et+1,Rt) look like? The true law W answers that question in principle, but W is a property of the world, not something the firm has access to. The firm must build its own learned approximation. We call that approximation the Economic World Model (EWM)—a world model in the control and planning sense, a learned object used to roll forward possible futures under candidate actions [21, 22, 23, 24, 25, 16, 17]. The qualifier economic marks a structural feature, not a stylistic one. The EWM is trained on a prediction-error loss (Empirical EWM estimator), but every input that lowers that loss—data, compute, parameters, refits, R&D campaigns—is itself priced in dollars on the firm’s books, and every reduction in predictive loss flows back into the firm’s expected return rate. The subsections below define the EWM, contrast it with a language model trained on a static snapshot, and lay down the channel histories that make per-channel scoring tractable.
EWM Definition
The EWM is the conditional next-cycle law the firm uses to forecast the joint (Ξt+1,Et+1,Rt) given its current information set Ft and a candidate action at. It is the only model of the future the firm has access to, so improving it is itself an allocation with first-order effect on Jt.
Definition 7Economic World Model
The Economic World Model (EWM) is the firm’s learned, filtration-respecting approximation to W. Given the information set Ft and a candidate action at, Wt returns a joint distribution over the next firm state, the next environment, and the cycle reward. Improving Wt is itself an allocation:
(Ξt+1,Et+1,Rτ)=Wt(⋅∣Ft,at)
Example
Suppose the corporation has a large transformer neural network that consumes supply-chain telemetry and geopolitical news; the firm uses that network to forecast how an Iran conflict will change oil prices, how those oil prices will change the value of the firm’s futures contracts, and what effect that change will have on shareholders’ equity.
Firm and Channel Histories
Because the firm sees the world only through its sensors, both Et and its own state Ξt enter the EWM as posteriors over noisy observations rather than as latent ground truth. The firm history Ht is the chronological log of every observation through cycle t—the canonical sufficient statistic in the partially-observed Markov decision process tradition [26, 27, 28, 29]. The channel histories Htk slice it channel by channel into (oτk,aτk,Rτ+1) rows. These per-channel slices are the tables the firm uses to fit the row laws of the marginal-return vector.
Definition 8Firm history
The firm history at time t is the chronological observation–action–reward log the firm has recorded through cycle t. The observation vector oτ is the sensor output generated by the latent corporation–environment state; the action aτ is what the firm did next; and Rτ=log(Kτ+1/Kτ) is the cycle-τ reward realized after that action.
Ht=o0o1⋮ot−1ota0a1⋮at−1–R1R2⋮Rt–
Definition 9Channel history
The channel history for channel k at time t is the channel-k slice of Ht, recording for each cycle in the firm’s lookback window the channel observation oτk, the channel action aτk, and the next realized log-equity reward.
Suppose the firm keeps a sensor-channel history of every dataset it has owned. Each row records the data inventory available before the cycle, the dataset or feed acquired in that cycle, how that data set improved backtests on different candidate models, and how much live trading was improved, as well as counterfactual simulations of what would have happened had the firm not acquired that data set.
Definition 10Firm filtration
The firm filtration at time t is the σ-algebra generated by the firm history. A random variable is Ft-measurable iff its value is determined by Ht. The family {Fs}s≥0 is what enforces the no-peeking discipline of the EWM: a forecast at time t may condition on Ft and on nothing resolved later.
Ft=σ(Ht)
LLMs are not economic world models
The filtration requirement is what separates an Economic World Model from an ordinary language model. At decision time t, an EWM may condition only on Ft and the candidate action at. A language model trained on a static corpus [30] can mix documents from before and after the event it is asked to predict, so its context can contain future information. The same no-peeking discipline that separates a forecasting model from a memorizing one has been the organizing principle of game-playing AI [31, 22, 21, 23], and the loss functions below make the difference explicit. For next-token modeling on a fixed snapshot, this is fine. As the primary EWM Wt without an externally imposed filtration discipline, it is not: held-out validation can only enforce filtration discipline if the holdout set is chronologically after the entire training corpus—a window that shrinks as internet-scale models train on ever more recent data. This results in very little data left for validation, and even less for robust benchmarking. Consequently, measured performance uncertainty remains high, and the small post-corpus window provides negligible information about how the model adapts to changing market regimes. The outcome is slower compounding of capital and structurally riskier decisions. A general LLM that is wrapped in a strict post-cutoff evaluation harness can still serve as a component or proposal mechanism; the categorical claim is about the bare model, not the wrapped system.
LLLM(Θ)=i∑ℓ(pΘ(xi∣ctxi),xi)(permutation-invariant over documents)
LEWM(Θ)=τ∈Ieval∑ℓ(Pτ(oτ+1,Rτ+1∣Fτ,aτ),(oτ+1,Rτ+1))(information order matters)
Suppose a language model is trained on a 2024 internet snapshot that contains articles, analyst notes, and Wikipedia edits explaining a market event from 2022. When that model learns the 2022 event, it can absorb the 2024 retrospective explanation of what happened. A filtration-respecting prediction model cannot do that: in a 2022 backtest, the training data must contain only information available up to the 2022 timeline.
Channel-Specific World Models
In principle the firm has one joint EWM Wt over the entire corporation–environment state. In practice that joint object is approximated by a collection of channel-specific world models, each trained on its own channel history Htk. These per-channel transition models are usually much simpler than a full simulator—a scaling law, a market-impact curve, a refit-decay model, or a search law is already a channel-world-model fragment. The split is a practical approximation, not a claim that the channels evolve independently; cross-channel coupling re-enters when the controller composes the rows of gt below.
Definition 11Channel-specific world model
In principle the firm has one joint EWM Wt over the whole corporation–environment state. In practice, a channel-specific world model is the channel-k conditional law over the next channel observation and reward, given the channel history Htk and a candidate channel action atk:
(ot+1k,Rt+1)∼Wtk(⋅Htk,atk),k∈{I,S,U,Z,Θ}.
Example
Suppose the corporation keeps an Investments-channel world model, WtI, trained specifically to forecast the value of assets available for purchase and how much trading them will impact their price. An Investments-specific world model asks: if the rest of the firm is held constant and the firm maintains a candidate portfolio I, how much expected equity growth will it produce?
The Portfolio Optimizer
Choosing how to spread a fixed pool of capital across competing assets so as to maximize a long-horizon utility of wealth is the canonical problem of portfolio optimization, with a literature that runs from Markowitz mean–variance allocation [32] and Kelly’s growth criterion [18], through Sharpe’s reward-to-volatility ratio [33] and Merton’s continuous-time program [34], to universal portfolios [35], robust mean–variance allocation [36], and the broader machinery of convex optimization and constrained stochastic optimal control [37, 16, 17]. The problem the corporation solves at each cycle is a multi-period instance of the same family: the channels of Ξt are the assets, at is the rebalancing trade, and Jt is the long-horizon log-utility. The novelty is the asset set: the firm allocates not only across tradable instruments but across sensors, actuators, parameters, and R&D on the same dollar axis.
We adopt the standard framing of model-predictive control: the EWM Wt supplies forecasts under candidate actions, and the policy G chooses the next allocation by solving a single-cycle convex inner problem over the per-channel return posteriors, then committing the chosen action and re-solving in the next cycle [38, 37, 16]. This section states the corporate optimization problem in its convex form and introduces the marginal-return vector that the rest of the blueprint estimates row by row.
The Corporate Optimization Problem
Stitching together the cumulative objective and the firm’s solvency, liquidity, and budget constraints gives the corporate program: the controller G picks the action that maximizes Jt subject to the constraints in the appendix. The full constraint set is collected in Program Constraints so the body can stay focused on the convex inner program.
Definition 12Corporate optimization problem
The corporate optimization problem chooses the policy G that maximizes the cumulative objective Jt, subject to budget, channel-liquidation, liquidity, and solvency constraints.
G∗=argGmaxJts.t. financial constraints.
Example
Suppose at cycle t AlphaFund has Kτdeploy=$2M and faces a candidate policy that proposes $900K investments, $400K sensors, $300K parameters, $250K R&D. The cumulative objective Jt is maximized at this allocation provided all four constraints clear: total spend $1.85M ≤ $2M (budget binds slack), no channel falls below its liquidation floor, and the liquidity and solvency reserves of Program Constraints are intact. If the proposal had instead been $2.2M, the budget constraint would bind first and the optimizer would reject the policy before any marginal-return comparison.
The Marginal Return Vector
Differentiating the common objective Jt with respect to the capital-allocation vector turns heterogeneous interventions—a researcher hire, a new alternative-data feed, a GPU, a position in AAPL, an execution-latency upgrade—into directly comparable marginal rates. Each entry of gt is the expected log-equity growth per marginal dollar invested in that channel; at the optimum every funded channel equates the same risk-adjusted shadow price of capital, gtk/σtk=λS,t∗ (Portfolio Optimization), which collapses to the bare equimarginal identity gtk=λt∗ only in the risk-neutral limit (κt→0, or per-channel dispersions σtk→0). The risk functional itself is general: Trsi Net writes the full corporate t-RSI in terms of any auditable uncertainty functional Ut, of which standard deviation is just the operational default. The next section instantiates this row by row for the quant firm.
Definition 13Marginal-return vector
The marginal-return vectorgt is the gradient of the cumulative objective Jt with respect to the cycle-t capital-allocation vector at. Each coordinate of gt tells the optimizer how much expected log-equity growth one extra dollar buys in that channel right now.
gt=∂at∂Jt
Example
Suppose the firm’s current estimates are gtS=0.2 per dollar (sensors) and gtI=0.1 per dollar (investments). Then the next $100 should go to sensors: $20 of expected future log-equity growth versus $10 from putting that $100 in the trading book.
For each channel k, we use the chain rule to expand the per-channel marginal returngtk along the trajectory through which a cycle-t dollar propagates. The equity sensitivity ∂Rτ/∂Ξτ says how much next-cycle reward changes when the corporation state moves; the propagation Jacobian ∂Ξτ/∂atk says how a dollar spent on channel k at time t moves the state at time τ. Summing their product over the planning horizon gives the dollar’s full contribution to Jt:
gtk=τ=t∑T+t−1∂Ξτ∂Rτ∂atk∂Ξτ
Example
Suppose AlphaFund onboards an IEX D-Limit route this cycle. That route enters Ut+1,Ut+2,… and shaves friction off every rebalance from then on. Each future τ contributes one term to gtU through ∂Rτ/∂Ξτ and ∂Ξτ/∂atU, so a route that pays back across thirty rebalances is priced as the sum of all thirty marginal contributions, not just the next one.
The horizon T introduces uncertainty into this pricing: the variance of cumulative reward ∑τRτ propagates through the rollout. T is therefore set at the point where additional cycles no longer meaningfully tighten the estimate once that propagating uncertainty is accounted for. This uncertainty is fundamental to the controller’s allocation problem: an honest pricing of capital must trade off the central tendency of forecasted returns against their dispersion. The most general statement of this is expected-utility portfolio optimization, which evaluates allocations under whatever utility functional the firm chooses over the joint distribution of channel returns. Under the simplest case of normally distributed returns this collapses to mean-variance portfolio optimization[32] and the per-channel Sharpe ratio gtk/σtk[33]—the form we use throughout the rest of the paper for simplicity; in production, more complex utility-of-distribution objectives are often preferred.
Portfolio Optimization details why this uncertainty necessitates the risk-adjusted form not only for the investment channel, but for the performance and optimal allocation of every channel.
Experimental Evidence of t-RSI
Thus far we have talked about a theoretical framework for probabilistic recursive self-improvement. Now we will present experimental evidence that this framework is operational. Trsi Net formally defines t-RSI as the signal-to-noise ratio of net improvement; the remaining subsections then estimate the marginal-return vector gt for the quant firm, taking each row of Ξt—investments, sensors, actuators, parameters, and R&D—in turn. Each subsection opens with the channel’s history Htk and channel-specific world model Wtk, derives the corresponding row of gt, and reports the fitted parameters that the controller of the previous section consumes. Investments is the only instantaneous row whose return is read directly off the broker statement; the other four are state-flow channels whose payouts arrive over future cycles and are therefore priced through the trajectory chain rule. The empirical content—data scaling, loss-to-edge linearization, the Chinchilla-style joint surface, the 929-experiment auto-research log law, and the continual-learning intersection—is what makes the marginal-ROI comparison of the previous section operational rather than rhetorical.
What t-RSI Measures
Why t-RSI is the thing to measure.
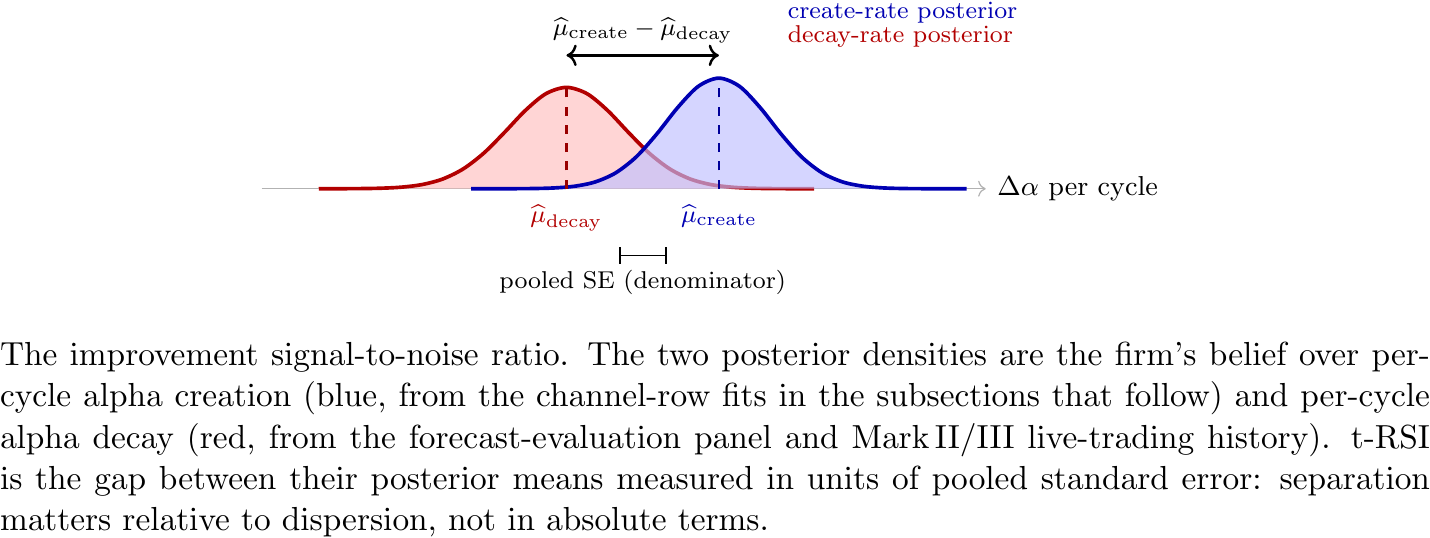
The differentiable-corporation thesis says the firm carries two posteriors at every cycle: one over alpha created per dollar spent on each channel, and one over alpha decayed from the deployed book. A controller that compounds is one that commits capital only when those two distributions are confidently separated — it believes it will create more alpha next cycle than the alpha already on the books erodes, and it believes it by enough margin that the call is unlikely to be noise. We call that standardized separation the improvement signal-to-noise ratio, written t-RSI by analogy with a two-sample t-statistic. The two distributions are not draws from one underlying process: they are posteriors over two different processes (create from the channel-row fits below, decay from the firm’s forecast-evaluation and live-trading panel). t-RSI is therefore framed as a standardized distance, not a hypothesis-test instrument.
Figure 2. The improvement signal-to-noise ratio. The two posterior densities are the firm’s belief over per-cycle alpha creation (blue, from the channel-row fits in the subsections that follow) and per-cycle alpha decay (red, from the forecast-evaluation panel and Mark II/III live-trading history). t-RSI is the gap between their posterior means measured in units of pooled standard error: separation matters relative to dispersion, not in absolute terms.
A positive t-RSI of, e.g., 2.5 means the create-rate posterior is centered 2.5 pooled standard errors above the decay-rate posterior. The firm’s controller does not commit capital to a candidate until that statistic clears a sealed-evaluator threshold (Certificate of monotone improvement); that gate is what makes compounding survive selection, and what distinguishes a self-improving corporation from one that promotes drift on noise. Equivalently, every row of the channel table below contributes one slice of the blue density, and the cycle’s investment decision is a draw from which slice the controller will pay for next.
Headline definition.
Write Δαcreatet:H for the firm’s posterior alpha creation over horizon H (the sum of per-channel contributions, with bookkeeping fixed in t-RSI Measurement Conventions), and Δαdecayt:H for the matching alpha-decay posterior. t-RSI is the standardized distance between them:
The channel-by-channel decomposition of Δαcreatet:H as a path integral along the planned allocation path, and the bootstrap propagation that supplies each SE, live in t-RSI Measurement Conventions; the operational walk-through of the headline three-month calculation lives in Three-Month t-RSI Calculation.
What the data presently say.
Empirically the firm’s own panel measures the decay rate as small and near zero. The data-derived headline reads λdecay from a per-asset alpha-decay estimator that fits the held-out forecast edge against deployment age once per asset and aggregates the resulting per-asset rate distribution robustly across the held-out asset universe (median + MAD/IQR summary; SE combines within-asset-cell dispersion with between-cell variability over training-run seeds and forecast horizons). The same qualitative picture holds in production: across 16 months of cumulative Mark II and Mark III live trading, every linear, rank, and distributional trend statistic against deployment age returns κ near zero. The data-derived headline t-RSI is therefore dominated by create-side dispersion, not by decay. The subsections that follow estimate the per-channel create-rate distribution one channel at a time; Headline t-RSI composes them into the headline t-RSI for the current operating point.
Investments as an Asset
What this channel is. Investments are the firm’s current production channel: capital positioned in the trading book and rebalanced by the controller. The EWM slice for this channel forecasts price-change distributions. Construction, scaling laws, and held-out benchmarks are deferred to a forthcoming companion paper; the empirical claims in this paper are channel-decomposed and do not depend on the companion-paper architecture. The controller turns those forecasts into a rebalance; the market function turns the rebalance into realized cash. This is the only row whose one-cycle return is observed directly from the broker ledger rather than inferred counterfactually [38, 39, 40, 41, 42, 43, 44, 45, 46].
Definition 15Investment marginal return
The investment marginal returngtI is the gradient with respect to the candidate trade ΔIt of expected return-per-dollar minus the learned execution friction ϕt. Investments are the only instantaneous channel: the gradient sees a single cycle because positions are marked to cash at the end of it.
gtI=∂ΔIt∂[atIΔItμt−ϕt(ΔIt,Ut,Et)]
Example
Suppose the EWM forecasts μt=8 bps for a $1M long in AAPL over the next bar against ϕt=3 bps of expected round-trip friction. Then gtI≈5 bps per dollar at this trade size. Doubling the size pushes ϕt up (slippage convex in size); the size optimum is where gtI falls to the marginal ROI λt∗.
What this means. The investments row tells the controller what one extra dollar of trading capital is worth right now: forecast edge μt on the candidate trade, minus the learned execution friction ϕt paid at execution. Of the three terms in Investment marginal return, the EWM forecast and the size dependence of ϕt are estimable from a backtest; the remainder of ϕt is not, and is the proprietary surface the rest of this subsection explains. Two of the three terms are public; one is not, and that asymmetry is why the live track record matters more than the backtest figure for this row.
Backtest.
ϕ deserves special emphasis: it mostly cannot be estimated from a backtest. Market impact admits a square-root-law approximation (Investments Supporting Equations), but the remainder—routing quality, venue- and broker-specific spreads, financing, adversarial response—is venue-, instrument-, size-, and time-of-day-specific and can only be learned by trading. The firm has executed approximately $400M of trades; that volume is the data behind its internal ϕ surface, which is proprietary for exactly the reason Investment marginal return makes plain—ϕ is the term the rest of the world cannot buy. The dated three-deployment-generation track record (Mark I/II/III) is reported in Deployment Parameters.
Sensors as an Asset
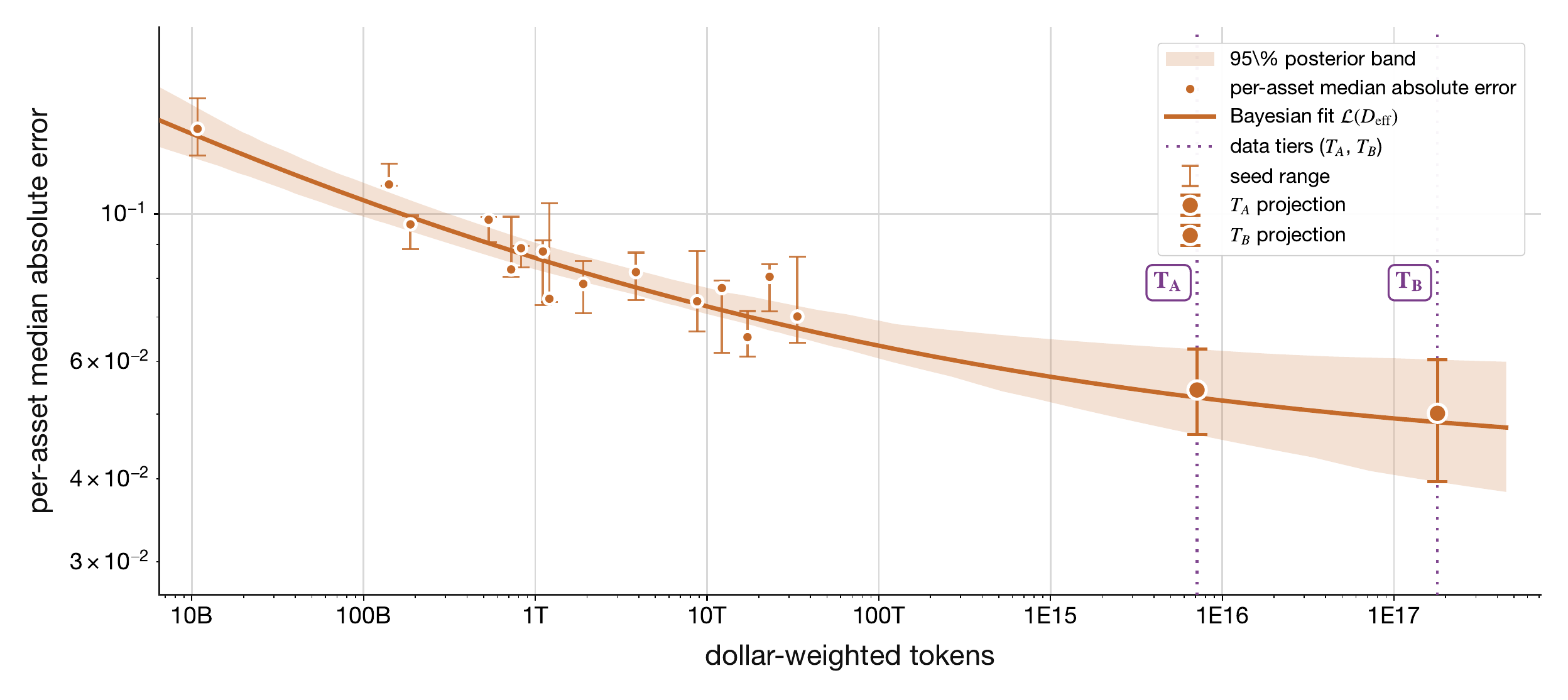
What this channel is. Sensors are purchases that enlarge the filtration Ft: market-data feeds, historical records, finer sampling, and any measurement that lets the EWM condition on more of the world. The empirical primitive is the data-scaling law, fit on the Muennighoff effective-data axis and the Hoffmann/Kaplan loss form [30, 9, 47, 48], with the underlying unit being the dollar-weighted bar in the spirit of information-driven sampling [49, 50, 51]. The body keeps only the local loss slope with respect to effective data; the fit protocol, prior choices, and controller-level chain rule are collected in Sensors Supporting Equations.
Definition 16Local data-scaling slope
The local data-scaling slope is the measured sensor primitive: how predictive loss changes when the effective dollar-weighted-token axis grows by one log-base-10 decade. The slope is the data-scaling decay rate times the reducible loss still available to be removed.
Deff∂Deff∂Lpred=−αDeff(Lpred−Lnoise)
Example
Suppose the fitted multi-seed sensor slope is αDeff=0.075 and the reducible loss component at the current Deff is ADeffDeff−αDeff=0.012. The local slope ∂Lpred/∂log10Deff=−αDeff⋅ADeffDeff−αDeff≈−9.0×10−4 per decade of Deff: each additional decade of effective dollar-weighted tokens removes about 9×10−4 of loss at this operating point, falling as the reducible component shrinks toward Lnoise.
Figure 3. Dollar-weighted tokens vs loss
Fitted parameters.
parameter
value
95% CI
R2
n
αDeff
0.156 (dimensionless)
[0.09, 0.229]
0.7619
45
R⋆
4.306 (epochs)
[2.324, 6.231]
0.7619
45
Lnoise
0.042 (loss)
[0.024, 0.061]
0.7619
45
ADeff
3.266 (loss scale)
[0.8072, 16.87]
0.7619
45
Equation
L(Deff)=0.042+3.266Deff−0.156
Deff=UD$[1+4.306(1−exp(−(E−1)/4.306))]
What this means. The fitted exponent says how much predictive error remains after the firm buys another decade of effective data. At the reported operating point, αDeff≈0.16 means a 10× increase in effective dollar-weighted tokens multiplies the reducible part of the loss by roughly 10−αDeff, or about 0.7: the model keeps about 70% of the reducible error and removes about 30%. The interval around αDeff is the uncertainty on that local data slope, not on trading alpha. R⋆ says when repeated passes over the same data stop behaving like fresh information, and Lnoise is the residual floor that more sensors cannot remove at the current model size and architecture; R&D moves architecture and therefore moves this floor (see Sensors Supporting Equations). This is why the chart is a sensor asset measurement: it prices data by the remaining predictive loss it can still reduce.
We expect this scaling law to continue, as scaling laws are some of the most well-established results across a variety of domains; as it turns out, our preliminary evidence suggests that quantitative trading demonstrates scaling laws as well. What the chart is actually pricing (effective dollar-weighted tokens, not number of predictive factors), the realistic order-of-magnitude scaling factors available against the current operating point, and the cross-domain evidence for power-law extrapolation are collected in Data Scaling.
Actuators as an Asset
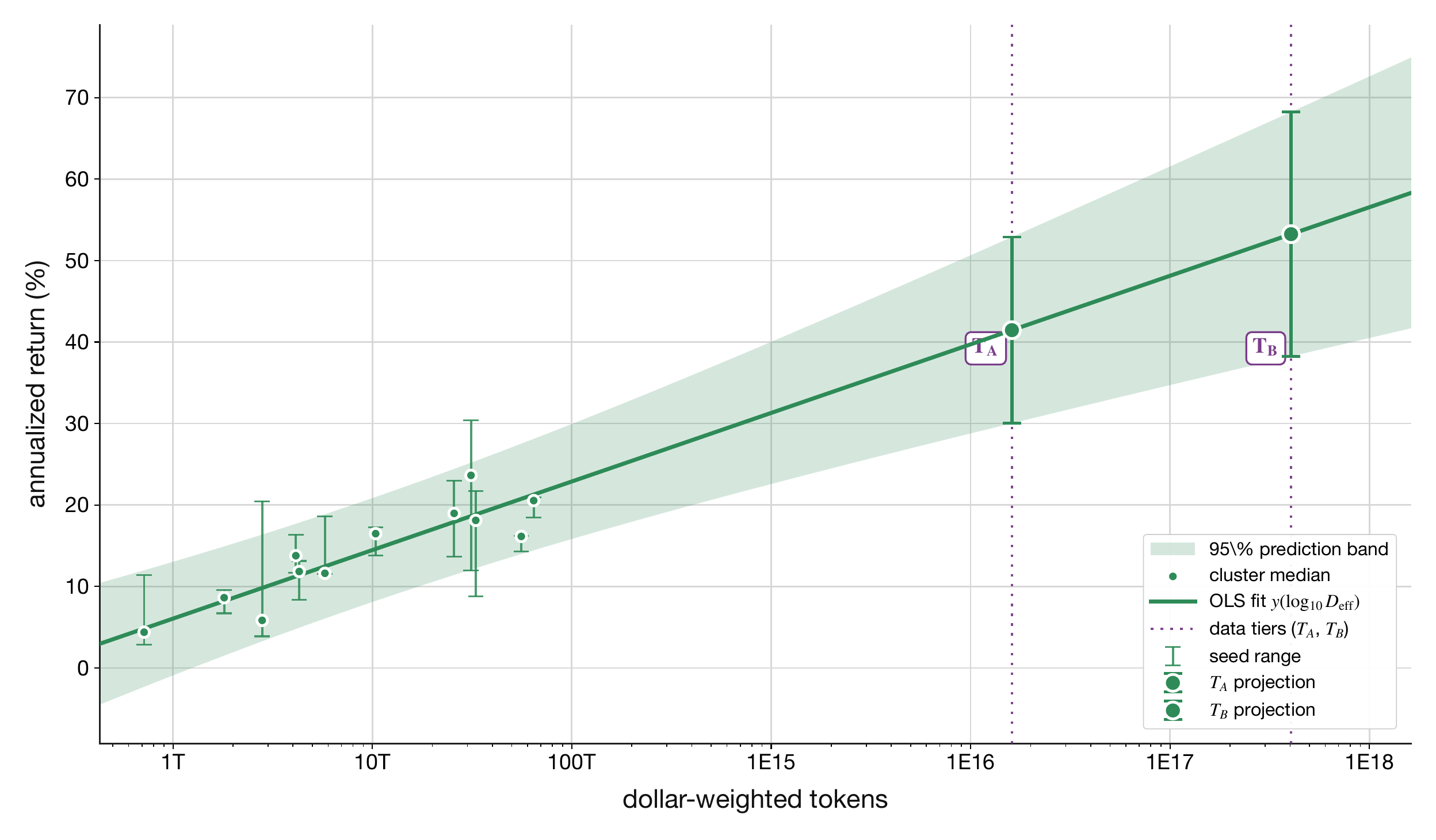
What this channel is. Actuators are the interfaces through which the controller can act. In the current quant-trading envelope, the measured actuator is the tradable asset universe: as the universe expands, the firm both trains on more dollar-weighted histories and gains more instruments through which forecasts can be deployed. The body keeps only the local data-performance slopes measured by that panel; the fit protocol, joint-path interpretation, and general actuator row gtU are collected in Actuators Supporting Equations.
Definition 17Local data-performance slopes
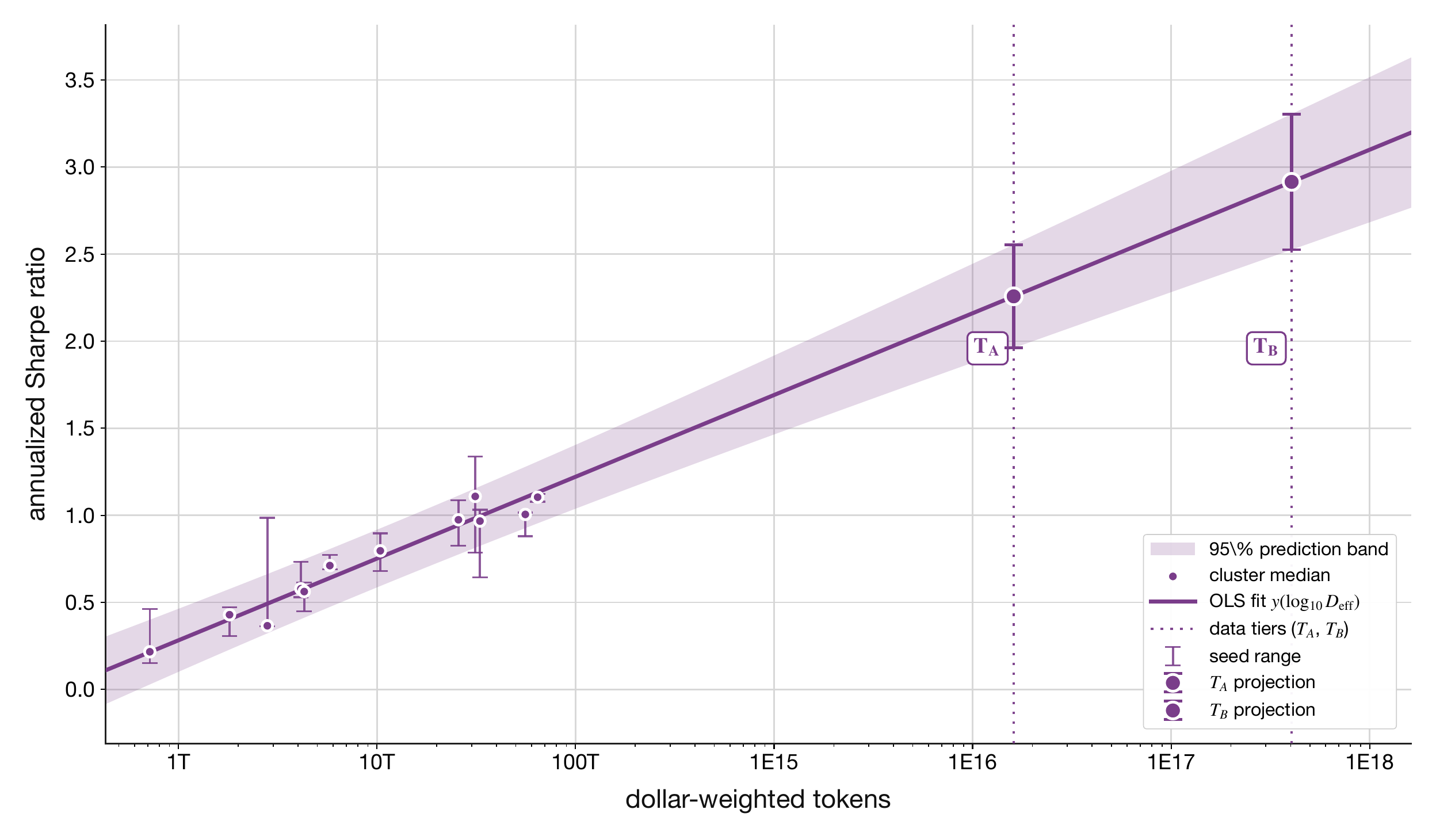
The local data-performance slopes are the measured actuator primitives in the current trading-envelope instance: annualized return and annualized Sharpe gained per decade of effective dollar-weighted data. In this section the actuator surface is the tradable asset universe, so the body reads these slopes directly from the panel rather than decomposing them into separate data, loss, execution, and friction terms.
Suppose the actuator panel’s OLS slope on annualized Sharpe is 0.32 per decade of Deff (cluster-median fit across the 12 universe sizes in the multi-seed scaling sweep). A universe expansion that absorbs an additional half-decade of dollar-weighted tokens predicts ∼0.16 Sharpe units of additional realized performance at the current operating point, before reserving capacity headroom against the impact baseline of Investments Supporting Equations.
Figure 4. Annualized return vs. dollar-weighted tokens.Figure 5. Annualized Sharpe ratio vs. dollar-weighted tokens.
Fitted parameters.
parameter
value
95% CI
R2
n
∂AnnRet/∂log10Deff
8.417 (pct points per decade)
[5.844, 10.99]
0.8043
12
AnnRet(TA)
41.46 (pct points)
[30.03, 52.88]
N/A
12
AnnRet(TB)
53.24 (pct points)
[38.24, 68.24]
N/A
12
∂Sharpe/∂log10Deff
0.4696 (Sharpe per decade)
[0.4027, 0.5364]
0.9499
12
Sharpe(TA)
2.258 (Sharpe)
[1.961, 2.554]
N/A
12
Sharpe(TB)
2.915 (Sharpe)
[2.526, 3.305]
N/A
12
Equation
AnnRet(Deff)=−94.96+8.417log10Deff
Sharpe(Deff)=−5.352+0.4696log10Deff
What this means. The actuator row asks whether expanding the tradable surface changes what the investment production function can do. The two slopes above are empirical between-N regressions: realized annualized return and realized annualized Sharpe per decade of effective dollar-weighted tokens. In this trading-envelope instance, the asset universe and the dollar-weighted data universe expand together, so the fitted slopes are read directly as local data-performance slopes rather than as separately identified data-only and actuator-only effects. The fitted slopes, their 95% confidence intervals, and the TA/TB extrapolation rows in the table above are all read directly off the actuator panel and the same OLS bookkeeping that draws the 95% prediction band on the chart. A note on sample size: the multi-seed sweep produces 15 universe sizes × 3 seeds =45 raw runs that anchor the sensor-row data-scaling fit, but the actuator-panel regression takes cluster medians across the three seeds at each universe size, so the n=12 reported in the parameter table is the 12-cluster-median count after dropping the three smallest universe sizes for which the per-seed median has insufficient evaluation breadth; the underlying 36-row (N,seed) panel is the object the cluster-by-N bootstrap of Three-Month t-RSI Calculation resamples. The parameter table’s n column reports the regression degrees-of-freedom unit (cluster medians), not the raw run count.
Potential scale.
We estimate the actuator-row scaling law could be extended over two tranches of source data that still satisfy the dollar-weighted-token construction of Three-Month t-RSI Calculation (dollar-denominated, strict time filtration); the corresponding TA and TB extrapolated Sharpe and annualized return are reported in the parameter table above. Tier TB is included because the underlying data class satisfies the same empirically measured dollar-weighted-token line fit that anchors Tier TA.
Tier TA – pure asset-price data: the catalogue of asset prices, quotes, trades, and order-book snapshots already commercially available across data brokers (global equities, futures, FX, rates, options, crypto, OTC fixings).
Tier TB – broader dollar-denominated time-series data: any other dollar-denominated series with a strict time index that respects the filtration (card panels, payments and settlement flows, insurance-claims tapes, payroll feeds, satellite- and geolocation-derived activity counts, public budget and procurement records), not restricted to tradable asset prices.
R&D as an Asset
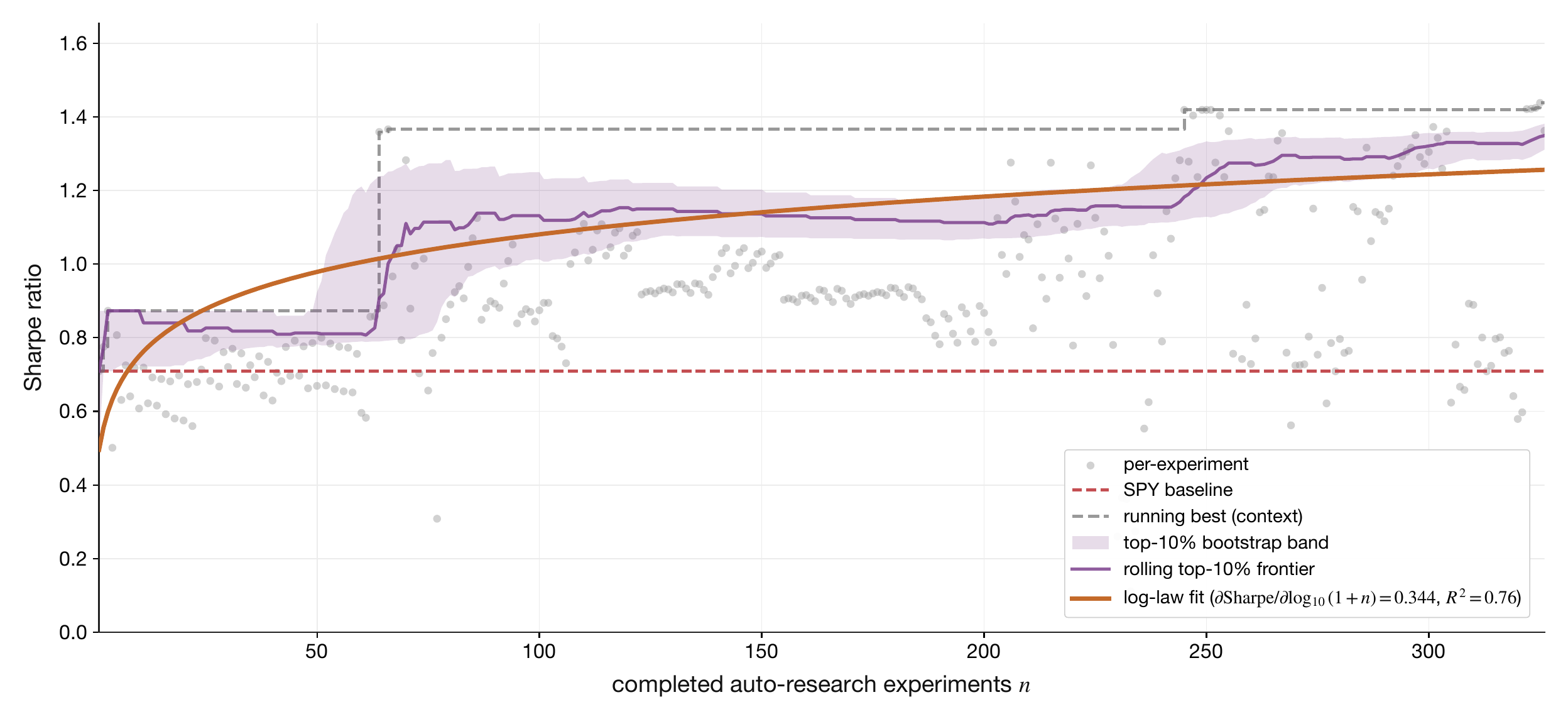
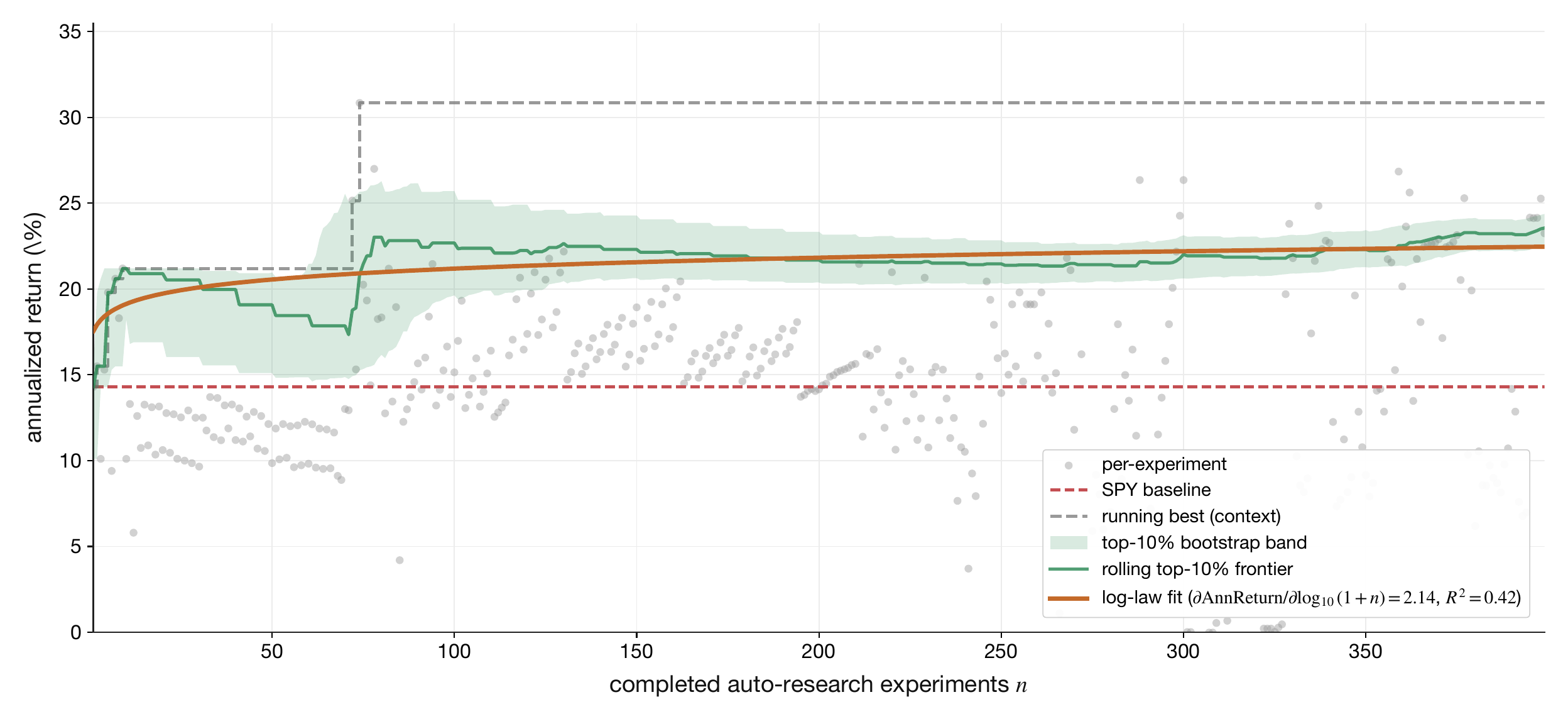
What this channel is. R&D is purchases that improve future search cycles: researcher labor, LLM API spend, GPU-hours, evaluation infrastructure, and search tooling. The empirical primitive the body reports is the derivative of the selected rolling upper-tail held-out frontier with respect to completed auto-research experiments, fit on the same axis for two metrics simultaneously — annualized Sharpe ratio and annualized return. The whitepaper manifest pins the headline frontier to the top-10% rolling upper tail for both Sharpe and annualized return, while the appendix reports the surrounding cutoff sensitivity scan. The held-out window is the canonical 1258-day validation split each campaign run reports against the 2516-day training period (see Channel Derivations); the §5.3/§5.4 sensor and actuator panels are evaluated on their own held-out splits as documented in Data Scaling. The body keeps only those two local derivatives; the dollar-to-experiment production function, the human/LLM allocation split, the architecture-quality scalar Γt, the search-scaling law Γt=ξlog10(1+Ntexp/N0), the chain rule gtZ, and the R&D transition law are collected in Channel Derivations.
Definition 18Experiments-performance slope
The experiments-performance slope is the body primitive for R&D: selected rolling upper-tail frontiers of validation Sharpe and validation annualized return across the strict-invalid- and sealed-holdout-filtered auto-research cohort, each regressed against log10(1+n) where n is the experiment index after sorting by run identifier. The headline derivatives ∂Sharpe/∂log10(1+n) and ∂AnnReturn/∂log10(1+n) report the gain on the selected frontier per decade of completed experiments; the matching intercepts β0,Sharpe and β0,AnnReturn pin the level at the start of the campaign.
Figure 6. Validation Sharpe vs. completed auto-research experiments. Per-experiment values are the gray scatter, the muted step is the running-best context line, the shaded band is the bootstrap interval for the selected top-10% rolling upper-tail frontier, and the orange curve is the selected log-law fit.Figure 7. Validation annualized return vs. completed auto-research experiments. The headline frontier is the selected top-10% rolling upper-tail fit; the running-best step remains only as muted context.
Fitted parameters.
parameter
value
95% CI
R2
n
β0,Sharpe
0.3921 (Sharpe)
[0.2258, 0.4964]
0.7563
326
∂Sharpe/∂log10(1+n)
0.3436 (Sharpe per decade of experiments)
[0.2978, 0.4153]
0.7563
326
β0,AnnReturn
16.91 (pct points)
[10.42, 19.12]
0.4159
399
∂AnnReturn/∂log10(1+n)
2.135 (pct points per decade of experiments)
[1.202, 4.792]
0.4159
399
Equation
Sharpefrontier(n)=0.3921+0.3436log10(1+n)
AnnReturnfrontier(n)=16.91+2.135log10(1+n)
What this means. The two fitted derivatives say what a ten-fold increase in completed auto-research experiments buys on the selected held-out frontier: ∂Sharpe/∂log10(1+nexp) Sharpe ratio points and ∂AnnReturn/∂log10(1+nexp) percentage points of annualized return. Each is the headline R&D primitive in the metric the firm actually optimizes against. The fitted curves are read off the report-selected top-10% rolling upper-tail frontiers of the strict-invalid- and sealed-holdout-filtered cohort; the running-best step remains in the figures only as muted context. Starting from the current campaign count ncurrentexp and projecting forward to ncurrentexp+Δn completed experiments, the additional Sharpe purchased is ∂log10(1+n)∂Sharpe[log10(1+ncurrentexp+Δn)−log10(1+ncurrentexp)], and the additional annualized return is the analogous local increment with ∂AnnReturn/∂log10(1+n). This is how the R&D row enters the t-RSI numerator: a marginal R&D dollar is priced through how many additional experiments it buys (Channel Derivations) and how much each completed experiment is currently shifting the selected frontier along the fitted curve.
Selection vs. structural scaling.
Across 929 auto-research experiments, the rolling top-10% frontier of held-out Sharpe rises log-linearly with completed-experiment count (slope ≈0.34 per decade). We note this is a selection statistic rather than a structural scaling law: the top-k% mean of n samples from a stationary distribution would also grow with n. The substantive question is whether the underlying distribution is shifting — for which the running median (rather than the top-10%) is the cleaner diagnostic, and we treat the present fit as a directional finding to be confirmed against that diagnostic in subsequent campaigns.
Why this fit, given that caveat.
The empirical methodology for studying auto-research is itself new: the only large-scale precedents we are aware of are the open-source single-GPU agent loop catalogued by [52] and the autonomous-R&D-capability evaluation harness of [53], neither of which prescribes a settled frontier-estimation protocol. Within that gap we have chosen a rolling top-quantile with a bootstrap confidence band rather than the more common running-best step. Running-best is a strict order statistic over an ever-growing sample: it is monotone in n by construction and is exactly the selection-bias regime that the deflated-Sharpe / backtest-overfitting literature documents as untrustworthy ([54, 51]). A rolling top-k% tail mean is a smoother, less brittle envelope of the same upper-tail behavior, and reporting a bootstrap CI alongside it surfaces the residual selection inflation directly. We do not claim this estimator is the right answer for auto-research scaling — only that it is a more defensible reading of the frontier than the running-best step at the same sample sizes, and that the eventual structural test against the running median (above) is what would convert it from a directional finding to a settled fit.
Parameters as an Asset
What this channel is. Parameters are model scale purchased through training compute. The marginal-return row sits on the joint Hoffmann/Chinchilla loss surface [30, 9]: an architecture-set noise floor, a model-size term, and a data term whose coefficients are pinned by a (Mt,Dt,At) sweep. The body keeps only the joint surface; the full chain-rule decomposition gtΘ, the compute-cost identity, and the worked example are collected in Channel Derivations. The complementary empirical question — how quickly deployed parameters go stale, i.e. the alpha-decay term that prices the cost of not refreshing Θt — is what the deployed history already lets us measure, and we report that here.
Definition 19Parameter marginal return
The parameter marginal returngtΘ chains parameter dollars → model size Mt→ predictive loss → expected return → objective. The model-size term is the Hoffmann/Chinchilla power law Parameters Joint Scaling; the divisor DtseenKtpass/ηttrain is the compute-cost identity Compute Cost Identity that converts an Mt slope into a dollars slope.
Suppose AlphaFund is currently training a 2×107-parameter EWM and is considering a 4× scale-up at fixed Dt. Under a Chinchilla αM(At)≈0.34, the model-size contribution to Lpred shrinks by roughly 1−4−0.34≈38%. Whether that is bought depends on the matching Dt side of the joint surface; the model-size sweep that pins αM(At) has not yet been run, so the parameter row is recorded symbolically.
What this means. With the model-scaling slopes still pending, the deployed evidence speaks to the other half of the parameters row: not how steep the loss surface is in Mt today, but how fast the deployed weights Θt themselves age out. That is the αdecay term the controller charges against every cycle the firm chooses not to refresh its parameters.
Empirical alpha-decay from parameter staleness.
The parameter row is also where the corporation books the time-rate alpha-decay term that enters Investment marginal return and the t-RSI numerator of Three-Month t-RSI Calculation. Running the forecast-evaluation panel pooled across three training-run seeds — effectively approximately three independent five-month training-run studies (127–128 assets per run, three forecast horizons, ∼150,000 held-out rows per horizon over the [2020-01-01, 2025-01-01) test window) — gives a per-asset median decay rate λeff∼2–4×10−4 per 60-minute cycle, with the per-asset Mann–Kendall slope on MAE-skill against deployment age centered near zero across the 127-asset universe. The same qualitative picture holds in production: across ∼16 months of cumulative Mark II and Mark III live trading (Deployment Parameters), every linear, rank, and distributional trend statistic against deployment age returns a κ near zero, with several leaning in the positive-trend direction. Empirically, then, the measured alpha decay sits at or below the panel’s resolution; the small magnitude is most plausibly attributable to the firm’s low ∼27× annual portfolio turnover, which holds deployed weights inside the regime where parameter drift is dominated by sampling noise. The data-derived λdecay that enters the headline t-RSI is therefore small and near zero. The per-horizon decay panels, fresh-vs-stale density panels, and per-asset λeff histogram are in Channel Derivations.
Model-scaling sweep is forthcoming.
The (Mt,Dt) Chinchilla-style grid that pins αM(At), AM(At), the training-efficiency term, and the model-size-dominates-data crossover is the obvious next sweep on the multi-seed scaling backbone. The current data lets the optimizer price decay (small, noise-dominated) but not yet model-size headroom; that sweep is queued as the next campaign and will refresh this row’s coefficients on completion.
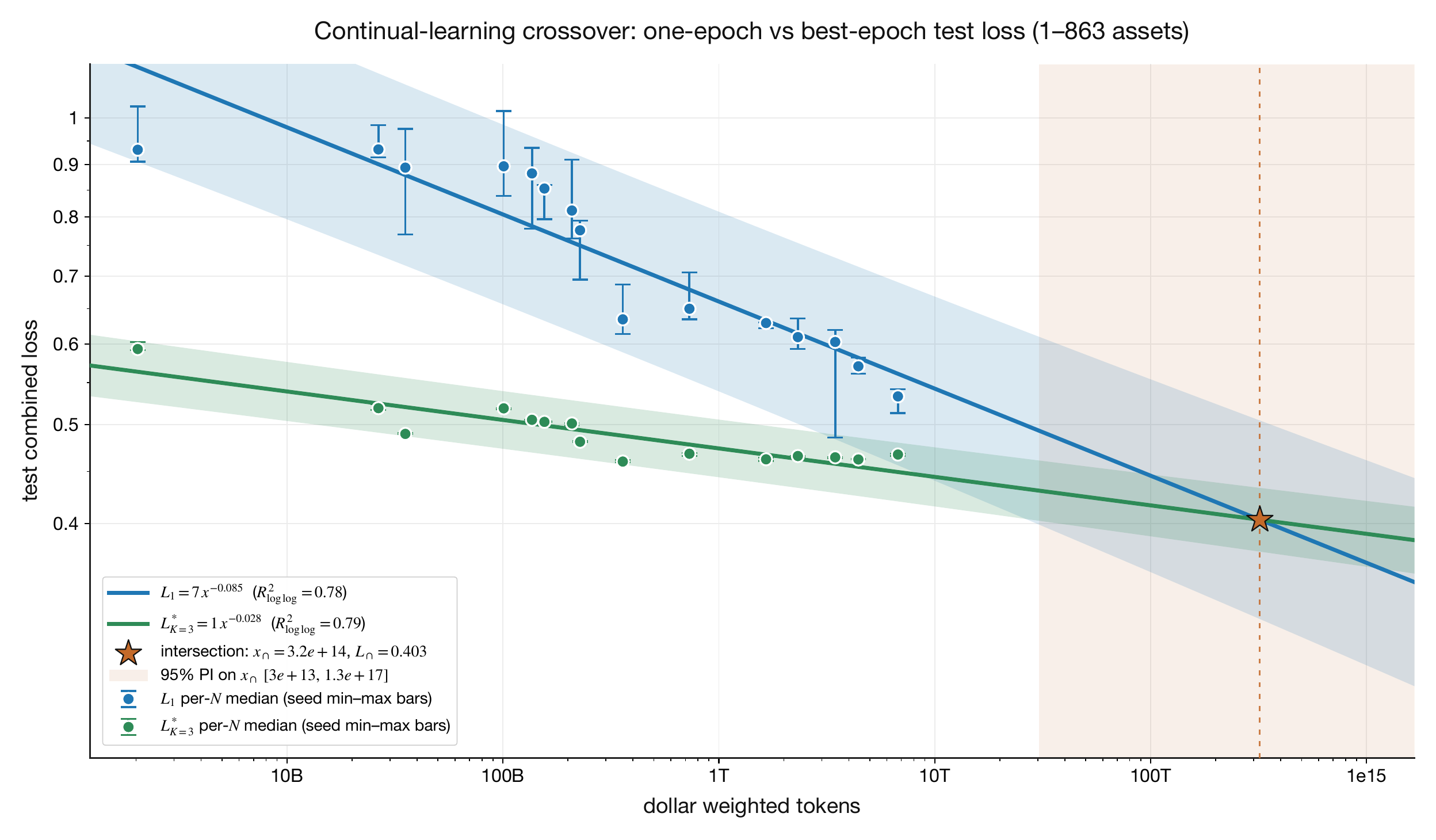
Continual Learning
The regime in which the model learns the relevant distribution in one pass, so the best validation loss after repeated epochs is no better than the loss after the first epoch. In this paper the boundary is the intersection between the one-epoch loss curve and the best-epoch loss curve. At that point epochbestloss→1: one repetition over the data is enough for the model to converge.
This is a structural statement about the parameters channel. Once the data can be learned in a single viewing, the firm exits the static train/validation/holdout regime and enters a walk-forward regime in which the deployed weights are refit every t+τ for some τ≪T, where T is the total length of the dataset. This is the same generalization regime observed at scale in modern language-model training, and operationally it is what is commonly called continual learning—data evaluated and trained prequentially, in chronological sequence.
Two consequences propagate forward. First, the variance of the expected-return estimator collapses: every training sample becomes a valid out-of-sample evaluation point at the next refit boundary, so the firm’s posterior on its own forward returns tightens monotonically with operating history. Second, the tighter posterior feeds back into both the architecture-search channel and the controller. Architecture search inside R&D gains confidence that a candidate represents a genuine improvement rather than a sampling fluke, and the risk-aware controller allocates more optimally across all five investment channels because σc,t is smaller, increasing the rate of improvement. Continual learning is therefore not just a downstream consequence of epochbestloss→1—it is also the mechanism by which the firm’s per-row uncertainties tighten.
Definition 20Continual-learning intersection
The continual-learning intersection is the dollar-weighted-token scale x∩ at which the single-pass (K=1) loss curve meets the best-of-K⋆-epoch loss curve, with both curves fit as Hoffmann-style power laws on D at fixed Mtint and shared loss floor L∞. Below x∩ the best-epoch curve is strictly tighter (additional passes over a small token budget reduce loss); at x∩ the two curves cross, and to the right of it epochbest loss →1: a single pass over the data is enough for the model to converge, so repeated epochs no longer help and most of the available history can be reserved for genuine evaluation rather than training. The two power-law exponents α1 and αK⋆ are independent and separately estimable; setting LK=1(x∩)=LK=K⋆(x∩) and solving for D gives x∩=(AK⋆/A1)1/(α1−αK⋆).
Suppose the corrected multi-seed fit puts the intersection at x∩≈3.2×1014 DWT and L∩≈0.40 test combined loss, with α1≈0.085 and αK=3⋆≈0.028. Once AlphaFund crosses this scale, the scaling-sweep architecture is in its prequential regime: train on the most recent slice, test on the rest—a holdout pattern unavailable to the multi-epoch regime.
Figure 8. One-epoch test loss and best-epoch test loss versus single-pass dollar-weighted tokens. The intersection marks the estimated entry into the Kt→1 continual-learning regime.
Fitted parameters.
parameter
value
95% CI
R2
n
α1
0.08548 (first-epoch loss slope)
[0.07194, 0.09903]
0.7805
45
αK=3∗
0.02795 (best-epoch loss slope)
[0.0236, 0.0323]
0.7867
45
x∩
3.204e+14 (dollar-weighted tokens)
[3.110e+13, 1.718e+17]
N/A
45
L∩
0.4035 (test combined loss)
[0.3028, 0.448]
N/A
45
The chart says that first-epoch loss is falling faster than best-epoch loss as the dollar-weighted-token budget grows. If those two power laws intersect, then the model no longer needs repeated passes to reach its best loss: the first pass is enough. Operationally, that means a smaller fraction of the available history is needed for training and a larger fraction can remain genuinely held out for testing. Taken to the limit, if the distribution can be inferred from a small enough slice of the data, continual learning becomes a prequential approximation: the firm learns from the latest examples while preserving most of the data stream as evaluation.
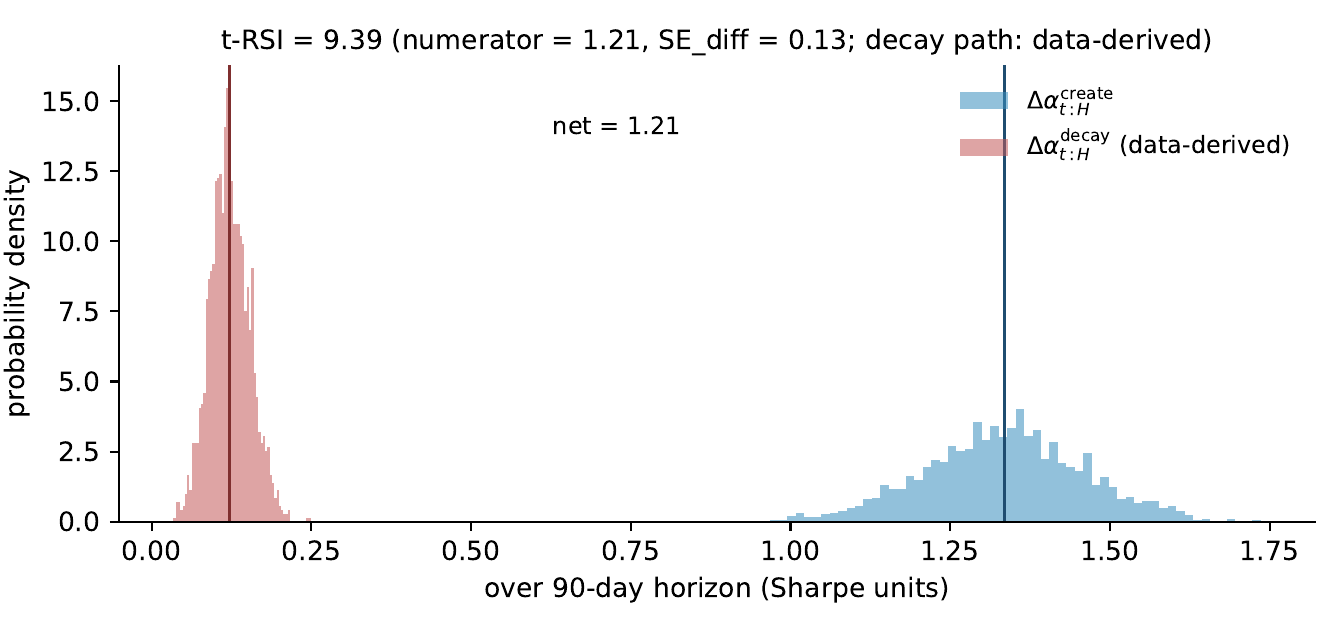
Headline t-RSI
At the current operating point the firm measures a positive standardized distance between its alpha-creation rate and its alpha-decay rate over the next quarter. Read the headline as: how many standard errors of the posterior of the difference the projected net alpha increment Δαt:Hnet sits above zero. The numerator is the difference of the posterior mean create rate and the posterior mean decay rate; the denominator is the standard error of that difference, propagated from an end-to-end bootstrap on the channel-row fits and the empirical alpha-decay panel cluster bootstrap. The headline conditions on the data-derived alpha-decay rate, which the firm’s forecast-evaluation panel and the 16 months of cumulative Mark II/III live trading measure as small and near zero (every linear, rank, and distributional trend statistic against deployment age returns a κ near zero, with several leaning in the positive-trend direction). The scope of the underlying extrapolation is narrow: the calculation only asks the data-scaling slope to continue roughly one and a half orders of magnitude past the in-sample Deff (one decade absorbed every two months over the three-month horizon), which is well inside the 3.5-OOM in-sample range of the sweep, and integrates that extension over a single three-month horizon.
Reading the magnitude.
The headline is large because the firm currently operates below the market-impact floor: at ∼$400k AUM and ∼27× annual turnover, individual orders sit well inside the regime where they can be split without measurable price impact, and the empirical impact contribution to the create-side bootstrap is indistinguishable from zero. The data-derived alpha-decay rate is also small (Three-Month t-RSI Calculation). With neither impact nor decay materially eroding the create-side gains, the standardized distance collapses to a near-pure read of the create-side dispersion, and that read is tight. A different operating point will read differently: at K-times current AUM the literature Q/ADV impact law [39, 55] reintroduces a capacity-driven Sharpe drag on the create side, and the headline compresses. Under a turnover trajectory consistent with the empirical decreasing-returns-to-scale pattern documented for active managers [56, 57], the same posterior reads 4.59 at K=10× AUM and 2.90 at K=100× AUM; under a worst-case trajectory in which annual turnover is held fixed at its current level, the headline crosses zero between K=10× and K=20× AUM. The full two-row capacity-sensitivity table is in Three-Month t-RSI Calculation. The thresholded form of this test statistic — the certificate of monotone improvement that gates whether a candidate update is admitted into the deployed model — is detailed in Improvement Certificate.
Figure 9. Posterior of the two t-RSI components over the 90-day horizon at the current operating point, under an end-to-end bootstrap of the channel-row fits. Light blue: Δαt:Hcreate, the posterior of the firm’s alpha-creation rate over the horizon (sensors+actuators plus the gross-of-carry R&D arm; researcher compensation flows through the accounting projection, not the creation-rate functional). Light red: Δαt:Hdecay, the posterior of the data-derived alpha-decay rate from Three-Month t-RSI Calculation (empirically small and near zero). The vertical solid lines mark the two posterior means; the dashed annotation is their difference. The title carries the standardized-distance t-RSI Trsi Net, the numerator (difference of means), and the denominator (SE of the difference).
Toward the Differentiable Corporation
AlphaFund is an early implementation of a differentiable corporation: a company whose operational decisions are being converted into auditable marginal-return estimates against future equity growth. In this architecture, each major use of capital—trading capital, data, execution infrastructure, model parameters, and R&D—becomes a row in a common optimization problem. The controller’s task is to compare those rows on the same dollar-denominated axis, allocate capital to the highest risk-adjusted marginal return, and update the estimates as realized outcomes arrive.
The evidence in § 5 measures several of these rows at the current operating point. Sensors and actuators are represented through data-performance scaling laws; R&D is represented through experiment-performance frontiers; parameters are represented through refit and decay measurements; and the combined create-versus-decay distance is summarized by t-RSI. These measurements make AlphaFund a concrete test case for the differentiable-corporation program.
Three Structural Facts
Pre-existing market with mandated price discovery. For t-RSI to be operationally measurable, the firm’s actions must be priced by an external mechanism at sub-cycle latency, with the prices observable and timestamped. Public equities satisfy this by federal mandate: every executed trade is reported and made public, timestamped to the nanosecond, against a market that has been continuously operating for longer than any other. The relevant point is not that this market is attractive — it is that the price-discovery machinery for every action the firm takes already exists, externally, at no construction cost and with no PMF term confounding ∂Equity/∂Company. Most candidate domains fail this condition: in nascent markets the firm has to build the price-discovery surface itself, which adds a learned-mechanism term to every gradient; in regulated-but-illiquid markets the prices exist but resolve too slowly to score per-cycle decisions. Quantitative trading is unusual in that this condition holds trivially.
Principal value capture. t-RSI requires that ∂Equity/∂Company be dominated by the firm’s own actions rather than by intermediated customer behavior. A trading firm is principal to its own predictions: carry is on the firm’s own positions against the market, not a per-call fee on a customer’s downstream use of a tool. The contrast with platform-AI clarifies what the condition rules out, not which business is preferable. A platform seller’s ∂Equity/∂Company is dominated by enterprise sales cycles, competitive substitution, and product–market fit — exogenous, lagged, customer-dependent terms whose variance swamps the marginal effect of any single internal improvement. The same model improvement that earns a platform $0.001M in API revenue might earn the principal $100M in carry; the difference is not which firm is better-run, but which firm has a directly measurable derivative against its own actions. Most industries fail this condition because their value capture flows through a customer-decision bottleneck whose noise drowns out the create-vs-decay signal the framework needs to identify, and the standard error on the relevant gradient grows accordingly.
API-complete operational degrees of freedom. Every operational decision in the firm is, in principle, a function call. Data ingestion is an API. Model training is an API. Capital allocation is an API. Trade execution is an API. Asset acquisition—new data licenses, brokerage accounts, exchange memberships—is an API. Each call produces a structured log that doubles as the causal record needed for a derivative against it. A clothing manufacturer’s production function bottlenecks on physical objects (textile sourcing, factory throughput, retail distribution); ∂Equity/∂(material blend) is not even well-defined as a derivative because the action space is not differentiable. Quantitative finance is the industry where it is.
The 15-bucket cross-industry ranking below makes this exclusive overlap explicit: quantitative finance is the only domain bucket in the top quintile jointly on theoretical LM exposure (0.94), automation-versus-augmentation occupational share (0.76), and self-reported API completeness, with high confidence [58, 59]. The AEI V4 dataset (Anthropic Economic Index) covers only 10.8% of O*net tasks by count; the missing 89% are overwhelmingly physical or manual. The empirical frontier of LM-mediated work is therefore the frontier of API-describable work—quantitative finance lies inside that hull while manufacturing, logistics, and on-site services lie outside.
Cross-industry exposure ranking across the 15 BEA-Detail domain buckets. Theoretical LM exposure is the labor-dollar-weighted AIOE LM score (Felten/Raj/Seamans). Automation share is the labor-dollar-weighted automation-vs-augmentation ratio from the AEI V4 (Tamkin et al., Anthropic Economic Index) classification. API completeness is a qualitative proxy from the upstream pipeline. Quantitative / Investment Finance (highlighted) is the only bucket in the top quintile on all three axes with high confidence.
Domain bucket
Theoretical
Automation
API
LM exposure
share
completeness
Legal Services
1.00
0.27
medium
Quantitative / Investment Finance
0.94
0.76
high
Banking & Credit
0.92
0.70
medium
Insurance
0.91
0.68
medium
Accounting & Finance Consulting
0.91
0.67
medium
Software / SaaS / IT Services
0.87
0.68
high
Data & Cloud Infrastructure
0.86
0.69
high
Management Consulting
0.81
0.70
medium
Architecture, Engineering & R&D
0.76
0.65
medium
Content, Media & Advertising
0.69
0.71
medium
Healthcare Admin-Heavy
0.62
0.63
medium
Physical Services & Trades
0.41
0.67
low
Manufacturing & Industrial
0.40
0.67
low
Logistics, Warehousing & Wholesale
0.39
0.69
low
Agriculture, Mining & Extraction
0.34
0.69
low
Channels Reinforce Each Other
The certificate of monotone improvement (Certificate of monotone improvement) fires on one channel at a time, but channels are linked through shared state, so marginal dollars do not decompose channel by channel. Formally, positive cross-partials of the cumulative objective on the active rows (Cross-channel supermodularity) yield supermodularity in the sense of Milgrom and Roberts [60]: a marginal dollar on channel j raises the marginal value of a dollar on channel k, and conversely. Local positivity can fail under capacity, attention, or saturation, so no global supermodular ordering is asserted. The continuation claim is probabilistic, not global (Certified-commit continuation bound): the certificate gates each commit at the prevailing operating point rather than relying on supermodularity everywhere, and while the cross-partials in Cross-channel supermodularity remain positive on those rows, an observed increase in the certified-commit improvement rate raises the posterior probability that the next commit also improves the loop, with the inequality read as an empirical row-law claim rather than a theorem.
Definition 21Cross-channel supermodularity
Cross-channel supermodularity says that the cumulative objective Jt has non-negative cross-partials on the rows the firm has identified [60]: a marginal dollar on channel j raises (or leaves unchanged) the marginal value of a dollar on channel k. This is a local statement on the active rows, not a global theorem; capacity, attention, and saturation can flip the sign off the operating point, which is why the continuation claim of Certified-commit continuation bound is probabilistic rather than supermodular-everywhere.
∂atj∂atk∂2Jt=0
Example
Suppose AlphaFund’s tradable universe widens from 127 to 160 names (an actuator add) while sensors absorb another decade of dollar-weighted tokens. The actuator add lifts the marginal value of the sensor dollar—more assets means more rows the new data can sharpen forecasts on—and the sensor add lifts the marginal value of the actuator dollar by raising the per-asset μt the widened surface deploys against. The cross-partial ∂2Jt/(∂atS∂atU) is non-negative at the current operating point.
Definition 22Certified-commit continuation bound
The certified-commit continuation bound is the probabilistic, row-law version of supermodularity: conditioning on a successful certified commit at cycle t—i.e. on the event Certt=1 from Certificate of monotone improvement—raises the posterior probability that the next certified commit also improves t-RSI. Read as an empirical row-law claim, not a global theorem: it says the firm’s track record of clearing the certificate is itself evidence that the next commit clears.
−Pr(Δt-RSIt+1>0,Ft)+Pr(Δt-RSIt+1>0,Ft,(31))=0
Example
Suppose the firm has cleared the certificate on ten consecutive Mark III refits, each raising the held-out three-month t-RSI by a posterior-mean 0.1 standardized units. The eleventh candidate update arrives. Conditioning on the prior ten certified commits raises the posterior probability that Δt-RSIt+1>0 above its unconditional rate; the strength of the lift is a posterior on the firm’s own row-law trajectory rather than a structural guarantee.
Drift Detection and Recovery
A differentiable corporation that keeps allocating through regime change needs three things; only the first is what section 5 measures in isolation.
That first requirement is fitted marginal-return laws with measurable standard errors on every operational degree of freedom.
The second is drift detection on the world model itself—an operational trigger when live inputs move outside the support on which those standard errors were identified.
The third is R&D throughput high enough that, once that trigger fires, the firm refits to the new regime before an obsolete mapping bleeds out deployable capital.
The certificate of Certificate of monotone improvement is evaluated on the same audited moments, so its economic content weakens exactly when drift invalidates the inferential basis for those errors.
On (2), the alpha-decay panel of § 5.8 already constitutes this surveillance and measures the decay rate as small and near zero on its measured horizon. On (3), the continual-learning construction of § 5.7 implies a refitting time constant that is short relative to the decay time constant summarized in (2), at the firm’s prevailing data-ingestion rate. The firm’s recovery rate therefore dominates its measured decay rate, which is what self-improvement under regime non-stationarity actually requires.
Definition 23Deployable-capital decomposition
The deployable-capital decomposition splits next-period equity into the slice generated internally by the realized cycle reward on the existing book (Kt+1int) and the slice supplied externally by outside investors against the firm’s certificate-cleared track record (Kt+1ext). External capital amplifies the loop only while each marginal externally supplied dollar clears the same risk-adjusted certificate of Certificate of monotone improvement after financing costs, dilution, market impact, and capacity effects.
Kt+1=Kt+1ext+Kt+1int
Example
Suppose at cycle t shareholders’ equity is Kt=$25M and the realized log-return on the existing book over the cycle is Rt=0.04, so Kt+1int=KteRt≈$26.02M. A certificate-cleared $5M outside-equity round closes that cycle (Kt+1ext=$5M), giving Kt+1≈$31.02M. If the marginal $5M had failed the certificate (financing cost above shadow price, or market-impact erosion past the capacity floor) the firm would have declined the round; the loop would have continued amplifying only off Kt+1int.
The Bitter Lesson for Capital
Sutton’s bitter lesson observes that the methods which win at scale in machine learning are the ones whose performance grows with computation, not the ones that encode hand-crafted human structure [61]. The capital analog is structurally identical and historically older: the firms that win at scale are the ones whose throughput grows with absorbed capital, not the ones whose decisions are bounded by the size of a fixed staff. The supermodular cross-partials of § 6.2 compound the internal loop at the rate the channels permit; the bitter lesson is that the loop does not stop there.
Once the corporation demonstrates, in its own operating record, that incremental capital reliably converts into measured row improvement and deployable edge, outside investors can treat that relationship itself as an investable object. The next-period deployable-capital identity (Deployable-capital decomposition) separates internally generated deployable capital Kt+1int from externally supplied capital Kt+1ext. External capital amplifies the loop only while each marginal externally supplied dollar clears the same risk-adjusted certificate after financing costs, dilution, market impact, and capacity effects.
Two things are worth mentioning. First, different financing instruments have norms—and in some cases strict bylaws—governing what they can and cannot invest in. As the world gets increasingly digitized, the instruments with more leeway and more quantitative discipline will, on average, outcompete those that cannot process as much information; this is its own selection pressure on the type of external capital a recursively improving corporation can absorb. Second, a self-improving corporation with improving capability attracts more capital; when the marginal certificate continues to clear, that increased capital further increases the rate of self-improvement, which increases the rate of returns, which in turn increases the rate of external investment. Some of that capital—particularly AUM and equity—does carry per-dollar performance decay through market impact and capacity. What matters is the race: when incoming capital buys data or architectures that raise expected return faster than market impact erodes alpha, the rate of self-improvement continues to climb and the rate of external investment accelerates with it—a positive feedback loop.
Completion Roadmap
The next phase is to close the remaining operational gradients. Salary and headcount cost, banking and cost of capital, hardware procurement and depreciation, asset-acquisition cost, and AUM acquisition cost are the remaining major terms in the corporate equation. Each term has a natural measurement surface: dollars in, operational capability out, and realized contribution to future equity growth. As those surfaces are instrumented, the corporation becomes progressively more legible to its own controller.
The completed object is a firm whose capital-allocation process is scored end to end: every major expenditure has a forecast, every forecast has a realized outcome, and every realized outcome updates the next allocation. The differentiable corporation is the limit of that process.
Beyond Quant Trading
The Economic World Model is a network trained on the joint distribution of priced economic data—a foundation model for allocation in the same sense that a large language model is a foundation model for text. Text describes economic activity; prices settle it; the same underlying forecast can therefore be executed at more than one depth in the real economy rather than only as a paper position.
The controller can be instantiated in three computational regimes, each removing one piece of hand engineering. The first is the one this blueprint develops in detail: a hand-factored chain rule whose per-channel scaling laws compose into a one-step gradient and equilibrate against the marginal ROI λt∗. The second replaces the hand factorization with a single neural Economic World Model trained end-to-end on the firm’s operating history; Jt becomes the discounted sum of predicted log-equity returns under a finite MPC roll-forward and ∇atJt is recovered by autodifferentiation through the rollout [16, 17]. The third parameterizes the allocation policy and lets gradients of cumulative log-equity flow back through the world model and into the policy itself: the differentiable-simulator paradigm of PILCO [62], the Dreamer family [63, 64, 23], and the broader differentiable-world-model line [21, 22]. The certificate of monotone improvement (Certificate of monotone improvement) extends across all three regimes: each candidate update is admissible only when the held-out t-RSI clears the Sharpe-margin threshold δ and the Fisher-information readiness floor εc on every active channel.
These regimes describe how the controller reasons; the question of what it acts on is orthogonal and develops along its own axis. If we take intelligence to be the capacity to acquire, preserve, and compound command over future resources, those resources need not arrive through a brokerage API. A forecast over future supply and demand has value because it implies future prices, constraints, and margins. The shallowest channel that realizes a predicted edge is a futures position; a deeper channel realizes the same edge as a sequence of actuators in Ξt (procurement, transport, refining, wholesale distribution) and captures the entire margin between input and output rather than the basis alone. Each version is the same economic prediction executed at a different depth, scored by the same per-dollar log-growth functional that the portfolio optimizer compares across heterogeneous channels in cycle t. The depth at which the firm operates is not a strategic preference but a Coasean comparison the framework already makes [65]: the firm verticalizes the next step of a production chain when two conditions hold together—the executing channel clears the certificate of Certificate of monotone improvement, and the certificate-corrected risk-adjusted cost of running that step in-house is lower than the market price of buying the same output. New actuators—humanoid platforms, AI agents, autonomous logistics services—enter the firm’s action set as soon as their success distributions are reliable enough for the EWM to learn and condition on. Because deeper execution demands a more capable W, the regimes and the depth axis are coupled: better reasoning unlocks deeper action, and deeper action enriches the operating record that the next regime trains on. At sufficient depth and scale the small-firm approximation no longer holds: a firm whose actions move corn prices, contract refining capacity, or absorb a meaningful slice of the financing pool perturbs Et+1 by its own choices. This is not a contradiction of the framework; it is absorbed by it. The firm’s filtration (Firm filtration) accumulates the joint record of its own actions and the world’s responses to them, so the EWM trained on Ft can in principle learn the reaction term that the small-firm limit zeroed out. Operationally the change is local: the same channel-row laws are refit on a richer history, and the certificate continues to gate every commit.
The standardized create-vs-decay distance, t-RSI (Trsi Net), is computable at AlphaFund. We believe quant trading is among the first domains where such a statistic is practically computable. A clothing retailer asking “does this material blend increase next-quarter equity” faces a numerator whose sign is contested between marketing-campaign quality, retail traffic, supply-chain cost, and the broader economic cycle; the standard error on the marginal effect is so large relative to the marginal effect itself that t-RSI is, in practice, undefined. A platform company selling tools—advertising slots, API tokens, software seats—inserts a product–market-fit layer between the loss its model minimizes and the revenue its balance sheet collects; the bridge is opaque, lagged, and customer-dependent, and the implied ∂Equity/∂(model improvement) is dominated by exogenous customer behavior rather than by the model. In both cases the underlying problem is structural: the standard errors on ∂Equity/∂Company are large relative to the effects they would measure at any reasonable sample size. The moat is therefore not the value of AlphaFund’s t-RSI. It is that t-RSI is practically computable in this firm and this industry. The single scalar that summarizes the legibility of a corporation to itself is, at the time of writing, much harder to construct elsewhere.
Conclusion
A differentiable corporation is a measurement architecture for compounding economic intelligence. It turns the firm from a collection of departments into a set of capital-allocation gradients, each estimated against future equity growth and updated through realized outcomes. AlphaFund’s current system implements the first measurable version of this architecture in quantitative trading. The path forward is to expand the measured channel rows, audit them prospectively, and use the resulting equation as the operating system for corporate self-improvement.
▸AppendixAccounting Bridge
Accounting Bridge
Accounting Projection
Definition 24Accounting projection
The accounting projectionπacct partitions the corporation into the four scalar quantities the cash-management side of the controller needs to clear its budget: the equity that compounds, the slice of equity deployable this cycle, the cash numeraire, and the reserves held back against constraints:
Πacct(Ξt)=KtKtdeployCashtKtreserve
Accounting projection πacct(Ξt) components. The four scalars are the cash-management slice of the firm’s books; the corresponding double-entry GAAP/SEC chart of accounts is left to the firm’s external balance-sheet simulation.
Symbol
Quantity
What it is
Kt
Shareholders’ equity
Total assets minus total liabilities, marked to current dollars. The scalar the firm compounds.
Ktdeploy
Deployable capital
The slice of equity the controller is free to allocate this cycle, after reserves and constraint set-asides.
Casht
Cash
Settled, unencumbered cash on the balance sheet. The numeraire every atk is denominated in.
Ktreserve
Reserves
Capital held back to satisfy the liquidity, solvency, and channel-liquidation constraints of Program Constraints.
Deployable Capital and Flow of Funds
The accounting projection of Accounting projection names the four scalars the controller needs; this subsection defines the two that move every cycle. Deployable capital fixes the stock: how much of equity is free to allocate after committed positions and reserves. Retained-earnings flow and Change in deployable capital are the flow: how realized cash from market activity, operating expenses, taxes, and reserve adjustments push the stock from one cycle to the next. The dot on E˙tretain marks a per-cycle flow into retained earnings; the Δ on ΔKtdeploy is the resulting cycle-over-cycle change in the deployable stock.
Definition 25Deployable capital
Deployable capitalKtdeploy is the slice of shareholders’ equity the controller is free to allocate in cycle t. It is total equity less the equity already committed to current positions, capitalized intangibles, and locked subscriptions (Ktcommitted), and less the reserves held back against the liquidity, solvency, and channel-liquidation constraints of Program Constraints (Ktreserve):
Ktdeploy=−Ktcommitted−Ktreserve+Kt
Example
Suppose AlphaFund’s shareholders’ equity is Kt=$25M. Of that, Ktcommitted=$18M is tied up in current trading positions, capitalized data licenses, and the GPU fleet, and Ktreserve=$5M is held against margin requirements and the solvency floor. Then Ktdeploy=25−18−5=$2M is the budget the next-cycle allocator clears against in Budget constraint.
Definition 26Retained-earnings flow
The retained-earnings flowE˙tretain is the cash-basis per-cycle change in retained earnings: realized cash from market activity Yt$ (the dollar output of the investments channel), plus non-operating cash income NonOptcash (interest, dividends received), less cost of revenue COGSt (data, inference, execution-side personnel), less operating expenses OpExt (R&D salaries, G&A, compliance), less taxes Taxt, less distributions Divt (dividends paid, buybacks). The dot, rather than a Δ, marks this as the instantaneous cycle-t flow into retained earnings; the corresponding stock change is recorded by Change in deployable capital.
Suppose in a given cycle AlphaFund books Yt$=$0.40M of realized trading PnL, COGSt=$0.05M (data and inference cost), OpExt=$0.20M (R&D salaries and G&A), NonOptcash=$0.01M (interest on cash), Taxt=$0.02M, and Divt=0. Then E˙tretain=0.40−0.05−0.20+0.01−0.02−0=$0.14M is the cycle-t flow into retained earnings.
Definition 27Change in deployable capital
The change in deployable capitalΔKtdeploy is the cycle-over-cycle net change in the deployable stock: the retained-earnings flow E˙tretain from Retained-earnings flow, less the cash flow into reserves ΔRest (margin top-ups, regulatory floor expansion). The Δ converts the per-cycle flow into the corresponding stock change that feeds the next cycle’s budget in Budget constraint:
ΔKtdeploy=−ΔRest+E˙tretain
Example
Continuing the previous example, suppose margin requirements grow by ΔRest=$0.04M this cycle (the firm’s open positions widened and exchange-set initial margin rose). Then ΔKtdeploy=0.14−0.04=$0.10M: the deployable stock Kt+1deploy rises by $0.10M, which is what the controller’s next-cycle budget reflects.
▸AppendixProgram Constraints
Program Constraints
Budget, Liquidation, Liquidity, Solvency
Definition 28Budget constraint
The budget constraint says that the total dollars allocated across channels in cycle τ cannot exceed the deployable capital available that cycle:
atI+atZ+atS+atΘ+atU=Ktdeploy
Example
Suppose AlphaFund has Kτdeploy=$2M available after reserves and existing commitments. If the controller proposes $900K to investments, $400K to sensors, $300K to parameters, and $250K to R&D, the allocation clears: the total is $1.85M. A $2.2M plan fails the budget constraint before any marginal-return calculation matters.
Definition 29Channel-liquidation constraint
The channel-liquidation constraint gives each channel a floor on how negative its allocation can be in one cycle. Negative allocations free capital, but only down to what can actually be liquidated from that channel:
atI=atI
Example
Suppose the firm wants to free cash from the sensor channel by canceling data contracts. If only $50K of subscriptions can be canceled this month, then aτS=−$50K. The controller may set aτS=−$25K, but not −$200K.
Definition 30Liquidity constraint
The liquidity constraint requires the cash line item to stay above an operational floor in every cycle. It is separate from solvency: a firm can have positive equity and still fail because it cannot meet near-term cash obligations:
Casht=Cashmin
Example
Suppose AlphaFund has positive equity but must keep Cashmin=$250K on hand for payroll, cloud bills, and margin calls. A candidate allocation that leaves only $100K cash is rejected even if the balance sheet remains solvent.
Definition 31Solvency constraint
The solvency constraint requires total assets to remain greater than total liabilities. If equity reaches zero, the log-equity reward is no longer defined and the firm has left the domain of the objective. The drawdown form of this requirement connects to coherent risk theory [66]:
Kt=0
Example
Suppose the firm has $10M of assets and $8M of liabilities. It is solvent. If a leveraged position falls far enough that assets drop to $7.5M while liabilities remain $8M, equity is negative and the policy has driven the firm through the solvency boundary.
▸AppendixEWM Details
EWM Details
EWM training and proper scoring.
The first two subsections collect the EWM-specific training derivations: the population KL objective the firm would minimize if it knew the true law, and the held-out empirical proper-scoring surrogate it actually trains against.
EWM Training Objectives
Definition 32EWM training objective (population)
The population EWM training objective is the expected Kullback–Leibler divergence between the true cycle-τ joint law of next observation and reward and the EWM’s forecast of that same law, averaged over decision times. Driving LEWM to zero would mean the EWM has recovered the filtration-respecting predictive law of what the firm will see next and what reward it will receive.
Suppose the next-cycle target is a joint pair: the oil-market observation oτ+1 and the realized cycle-τ reward Rτ after the firm’s futures allocation. The EWM commits to Pτ before those quantities resolve; the KL term compares that forecast to the true conditional law. The true law is not observed directly, so Empirical EWM estimator supplies the empirical proper-scoring surrogate.
Definition 33Empirical EWM estimator
The empirical EWM estimator is the proper-scoring-rule sum over a held-out evaluation index Ieval. Choosing a proper rule (e.g. negative log-likelihood, CRPS, or the energy score) makes minimizing LEWM asymptotically equivalent to minimizing the population KL of EWM training objective (population), provided Ieval contains no information resolved after the training cutoff. Each held-out row scores the EWM’s joint forecast against the realized next observation and reward.
Suppose the current evaluation window is the most recent 245 trading days held strictly after the training cutoff, and the universe is the 128 most-liquid common assets. Each held-out day supplies the realized next observation vector and reward sample; the proper score sums those realized samples against the forecast law the EWM emitted before the day resolved.
From Population KL to Empirical Proper Scoring
In practice the firm cannot evaluate EWM training objective (population) directly: it does not know Pτtrue. What it has are realized samples (oτ+1,Rτ) drawn from Pτtrue, and a standard fact: minimizing the expected log-score of a candidate density against samples from P is equivalent—up to the entropy of P, which is constant in the candidate P—to minimizing KL(P∥P)[67]. The empirical estimator the firm actually trains is the proper-scoring-rule sum of Empirical EWM estimator; point forecasts such as Rτ are summaries of Pτ. Driving LEWM down on a properly held-out evaluation index Ieval is the firm’s empirical handle on the population KL objective.
Filtration discipline.
The next subsection is filtration-specific: it explains why the EWM is conditioned on the firm filtration Ft rather than the latent joint state, what filtration enlargement means under sensor spend, and the no-peeking discipline that separates an EWM from a static language model.
Why the Conditioning is on the Filtration
In Economic World Model the EWM is fed Ft, not the latent joint state (Ξt,Et) that the true law W of True corporate transition takes as input. The asymmetry is there because the firm does not actually have access to (Ξt,Et). Two things go wrong. First, the environment Et—prices, order flow, regime variables, counterparty behavior, the news cycle—is observed only through the noisy projections that reach the firm’s sensors. Second, even the firm’s own state Ξt is not directly observed: the dollar marks atk that compose it are produced by the mark-to-market projection of Accounting projection, not by realized trades, so quantities such as the firm’s exact equity, the fair value of its positions, or the replacement cost of its model weights are themselves estimates carrying uncertainty. The firm only knows what its balance sheet is worth when it actually liquidates a position into the market.
What the firm has instead are sensor observations of both the environment and itself, accumulated over time. In this partially-observed setting the most informative summary the firm has access to is the history of those observations [26, 27, 28, 29]. A single observation is a noisy projection of the latent joint state, and the firm’s view of Eτ collects market data, order-book state, corporate actions, execution telemetry, financing constraints, filings, news, and any alternative-data streams the firm has bought into. Its view of itself collects the firm’s own actions, broker statements, mark-to-market valuations of every line of Ξτ, and the realized log-equity reward Rτ of Per-period reward.
Concrete examples in and out of Ft.
At any decision time t, events like “last Friday’s NVDA close exceeded $500,” “the firm’s GPU cluster grew from 64 to 128 cards in March,” and “last quarter’s options-flow feed produced a 3% lift in the model’s Sharpe” are inside Ft; events like “next Wednesday’s CPI print exceeds 3.5%,” “the architecture search the firm is about to launch will improve loss by more than 5%,” and “the trade the firm is about to place will close in profit” are outside it.
Filtration enlargement under sensor spend.
The firm filtration of Firm filtration is not static. When the firm spends capital on the sensor channel S—buying a new data feed, lengthening its historical archive, or sampling at finer resolution—it strictly enlarges Ft in the standard probability-theory sense: the post-purchase filtration admits events that the pre-purchase filtration could not resolve. The data-scaling slope of Data Scaling Fit Loss is the empirical rate at which spending dollars on the sensor channel reduces the population KL of EWM training objective (population): better filtration ⇒ tighter forecasts ⇒ lower KL.
Filtration discipline.
The EWM must respect the decision-time filtration of Firm filtration. A forecast for cycle t may condition on Ft; it may not condition on information revealed after the decision is made. The same discipline applies to features, labels, retrieved context, backtests, validation windows, and model-selection procedures. General language models [30] may enter the system as proposal mechanisms or components of the research process, but economic prediction is evaluated by chronological, filtration-respecting outcomes.
▸AppendixPortfolio Optimization
Portfolio Optimization
Shadow Price of Capital
For a single-cycle allocation problem, the Lagrangian associated with the deployable-capital constraint is Lt(at,λt):=Jt−λt(∑kaτk−Kτdeploy). The Karush–Kuhn–Tucker conditions yield, for every channel funded at the optimum, the equimarginal identity below; for every unfunded channel, the corresponding inequality gtk∗≤λt∗ holds. The multiplier λt∗ is the shadow price of capital: the marginal Jt produced by one additional dollar of deployable equity, regardless of where it is spent.
gtI=λt∗
For every unfunded channel, gtk∗≤λt∗ with atk∗=0. If any channel’s marginal return per dollar exceeds λt∗, capital is underallocated to it and the controller’s next step raises that allocation until the equimarginal identity holds again.
Markowitz Mean--Variance Form
Fix a cycle t and let gt=(gtk)k∈RK be the vector of posterior-mean marginal returns, and Σt∈RK×K the posterior covariance of those returns across channels [32, 37]. The controller solves the standard mean–variance program
where κt>0 is the firm’s effective risk-aversion (the Arrow–Pratt curvature of Jt around the operating point), Ktdeploy is deployable equity, and atk are channel-level floors (lumpy hires, minimum subscription tiers, contractual leases). With Σt≻0 the objective is strictly concave and the feasible set is polyhedral, so Markowitz Program has a unique optimum [37]. Diagonal entries Σtkk=(σtk)2 are the per-channel dispersions of the row posteriors Ptk; off-diagonal entries are the cross-channel covariances and are a future empirical refinement (a diagonal Σt recovers an independent-channel solve and is the operational default).
Black--Litterman Form with EWM Views
The Markowitz form treats gt as a point estimate. The Black–Litterman construction makes the EWM’s role explicit by combining a market-equilibrium prior with the EWM’s forecast as a set of views [68, 69]. Let Πt∈RK be the prior mean of marginal returns and let the EWM forecast supply q linear views
Pgt=qt+εt,εt∼N(0,Ωt),
where P∈Rq×K picks out the channels each view ranges over, qt=gtEWM is the EWM’s forecast, and Ωt encodes the EWM’s posterior covariance. Combining the prior gt∼N(Πt,τΣt) with the views via Bayes’ rule gives the closed-form Black–Litterman posterior
with τ∈(0,1] a scalar credence on the prior. The controller then plugs (gtBL,ΣtBL) into Markowitz Program in place of (gt,Σt). Ωt→0 (perfect EWM) reproduces the Markowitz solve over the EWM forecasts alone; Ωt→∞ (no EWM signal) collapses to the equilibrium prior.
Multi-Period Rollout and the Sharpe-Equimarginal Limit
The multi-period program is the model-predictive rollout of Markowitz Program over a finite horizon T[38, 16, 17]: at cycle t the controller solves
subject to the budget, floor, and inter-cycle state-transition constraints under Wt. The optimizer commits only at∗, observes Rt and the realized next state, refits Wt on the augmented histories, and re-solves at t+1. The first-order conditions of Markowitz Program (or of any single cycle of Mpc Rollforward) recover the operational form the controller actually deploys: writing the Lagrangian with multiplier λS,t∗ on the budget constraint, every funded channel satisfies
gtk−κt(Σtat∗)k=λS,t∗for all k with atk∗>0.
With diagonal Σt and a homogeneous risk scale, this collapses to the Sharpe-equimarginal rule gtk/σtk=λS,t∗, which generalizes the bare equimarginal identity [33, 32]. As the variance penalty vanishes (κt→0), Sharpe Equimarginal collapses to gtk=λt∗ and recovers the risk-neutral shadow price exactly.
Receding-Horizon Use of the EWM
The portfolio optimizer G of Corporate optimization problem consumes Wt in a receding-horizon loop. The object it would solve in principle is the Bellman recursion over the joint state,
V(Ξ,E)=asup{R(Ξ,E,a)+γE[V(Ξ′,E′)]},
the standard dynamic-programming statement of the corporate optimization in Corporate optimization problem[38, 17]. The factor γ is not a time-preference discount: Jt in Cumulative objective is undiscounted. It is a stand-in for the increasing per-cycle cost of further rollouts paired with the decreasing residual improvement those rollouts deliver, which is what bounds the planning horizon T in practice. The recursion is the philosophical content of self-improvement: the firm chooses allocations partly for how they reshape its own future cognitive configuration via Θ. Closed-form V is intractable for any realistic firm—the joint state space Ξ×E is high-dimensional, partially observed, and non-stationary.
The firm therefore solves the Bellman recursion approximately via model-predictive control [38, 37, 17]: at each cycle G rolls candidate trajectories forward under Wt over the finite horizon T, finds the trajectory that maximizes the truncated cumulative objective Jt of Cumulative objective, executes the first allocation at⋆, observes Rt and the realized next state, refits Wt on the augmented histories {Ht+1k}k, and re-solves. This is the standard equivalence between approximate dynamic programming, MPC, and model-based reinforcement learning when the transition is learned from data [38, 22, 23, 21, 17].
▸Appendixt-RSI Details
t-RSI Details
t-RSI Measurement Conventions
This appendix collects the bookkeeping conventions used by the body’s t-RSI calculation in Trsi Net and the headline three-month calculation that follows. The full step-through (numerator decomposition, dispersion identity, LOO R2 check, and end-to-end bootstrap protocol) lives in the formal paper’s three-month-t-RSI appendix; the conventions here are what the channel-row fits below assume so the numerator and denominator compose without unit drift.
Filtration discipline.
t-RSI is a held-out statistic. Both the numerator E[Δαt:Hnet∣Ft] and the dispersion Ut(Δαt:Hnet) are computed under the same no-peeking discipline that governs the EWM training loss (Empirical EWM estimator): every channel-row fit that feeds the t-RSI calculation is required to be reproducible from Ft alone, with no information resolved after the cycle-t cutoff entering either the slope estimate or its confidence band.
Horizon H.
The horizon is fixed in calendar time, not in operating cycles, so the calculation composes with arbitrary cycle frequencies. The headline calculation uses H=90 days.
Uncertainty functional Ut.
The t-RSI denominator is general: any auditable functional of the projected net-improvement distribution will do. The operational default is standard deviation under an end-to-end cluster-bootstrap of the channel-row fits (sensors and actuators bootstrapped cluster-by-N; the R&D derivative ∂Sharpe/∂log10(1+n) uses an SE derived from its selected-frontier bootstrap interval). Closed-form Pearson cross-checks use LOO R2 on the channel-row derivatives; the headline is the more conservative of the two propagation flavours.
Sign convention.
A positive t-RSI means net alpha creation outpaces alpha decay over H by that many standard errors of the firm’s posterior dispersion. The certificate of monotone improvement (Certificate of monotone improvement) thresholds this same statistic at ζ=δ/Ut channel-by-channel; commits below threshold are rejected by the controller.
From channel rows to the create-rate posterior.
The channel-row fits in the §5 body are written as objective gradients gtk=∂Jt/∂atk. To talk about alpha created per dollar invested we use the channel alpha gradient,
ψtk:=∂atk∂αtcyc=∂Jt/∂αtcycgtk.
For a planning horizon H measured in corporate cycles, the finite-horizon alpha created by channel k is the path integral of this gradient along the planned allocation path,
Δαt:Hcreate,k≈∫atkatk+Δat:Hkψtk(a)da.
Summing creation across channels gives the firm’s posterior alpha-creation rate over the horizon used as the numerator of Trsi Net,
Δαcreatet:H=k∑Δαcreate,kt:H.
The matching posterior alpha-decay rate Δαdecayt:H is estimated separately from the firm’s forecast-evaluation panel and the Mark II/III live-trading history; the full panel construction lives in Three-Month t-RSI Calculation.
SE propagation.
Each standard error appearing in Trsi Net is the SE of a posterior mean. The channel-fit bootstrap propagates input parameters through Normal(θ,SE(θ)) noise, so the standard deviation of the resulting bootstrap sample is itself the SE of the posterior mean; no further 1/n rescaling is applied. The construction of Trsi Net is structurally identical to a two-sample t-statistic; the operational walk-through lives in Three-Month t-RSI Calculation.
Three-Month t-RSI Calculation
This appendix is the operational walk-through of the headline three-month t-RSI reported in section 5; it documents the numerical inputs and the bootstrap-posterior moments that compose the standardized distance.
Numerator.
The difference of the posterior mean alpha-creation rate and the posterior mean alpha-decay rate over the H=90-day horizon, Δαcreatet:H−Δαdecayt:H, with the create-side composed of:
Sensors + actuators. The local Sharpe-data slope of Local data-performance slopes gives Sharpe gain per decade of effective dollar-weighted tokens absorbed; the sensors row supplies the rate at which decades are absorbed (the headline calculation uses β=1 decade per two months, i.e. 1.5 decades over the three-month horizon). Sensors enter through the actuator-panel slope rather than as a separate create-side term because the panel already measures realized performance along the joint asset-universe and data-universe expansion path.
R&D / architecture search. The R&D contribution is the local increment of the fitted selected-frontier experiments-performance law (Experiments-performance slope) between the current campaign count ncurrentexp and the projected end-of-horizon count ncurrentexp+Δn. The increment is ∂log10(1+n)∂Sharpe[log10(1+ncurrentexp+Δn)−log10(1+ncurrentexp)], evaluated on the report-selected top-10% Sharpe frontier so the create-side reads in the same Sharpe units as the sensors+actuators leg. The horizon experiment count is Δn=ρexpnresearchersH with ρexp the firm’s current experiments-per-researcher-day throughput from the auto-research campaign (the dollar-to-experiment conversion of Rnd Experiment Throughput blends human-researcher and LLM/agent throughput at their per-arm productivity rates ρthuman and ρtLLM; the optimizer chooses the mix endogenously). The derivative is reported gross of researcher carry: compensation is an accounting flow on the balance sheet, not a deduction from the alpha-creation rate.
Decay term.
The headline path uses the empirical λdecay from a per-asset alpha-decay estimator: an exponential decay rate of held-out forecast edge against deployment age is fitted once per asset, and the resulting per-asset rate distribution is aggregated to a single portfolio-level rate with a robust median + MAD/IQR summary. The reported SE combines within-cell MAD-derived dispersion with the between-cell SD across training-run seeds and forecast horizons, taking the more conservative of the two so the denominator does not understate dependence between cells that share assets. The bootstrap samples λ∼N(λ,SE(λ)), maps each draw through 1−e−λHcycles to obtain a horizon Sharpe-loss draw, and reports the resulting mean and SE. The measured κ sits near zero across every linear, rank, and distributional trend statistic against deployment age, and a majority of held-out assets show no monotonic edge decay, so the data-derived decay term contributes a small mean with a tight SE rather than an aggressive Sharpe-loss point estimate.
Denominator.
The standard error of the numerator, SE2(Δαcreatet:H)+SE2(Δαdecayt:H), propagated from end-to-end cluster-bootstrap of the channel-row fits: the actuator slope is resampled from a Gaussian with the published SE; the R&D derivative uses an SE derived from the selected Sharpe-frontier bootstrap interval; the decay draws are sampled as described above. For each draw the create and decay legs are summed independently and the empirical SD across Nboot=2000 draws is the reported SE of each posterior mean. Because each input parameter enters the bootstrap through parameter noise, the resulting SD is itself the SE of the posterior mean – no further 1/n rescaling is required.
Audit trail.
The numerical inputs the calculation consumes are visible in the figure title written alongside the create / decay posterior chart; the readiness audit cross-references the headline t-RSI row against the per-channel Fisher-information thresholds the certificate gates against.
Capacity sensitivity.
The headline conditions on the firm’s current operating point, where the realized per-trade Q/ADV sits below the impact floor and the empirical impact contribution is indistinguishable from zero. As AUM grows that condition cannot hold indefinitely: the literature square-root impact law [39, 55] implies a per-horizon Sharpe drag that scales with the size of executed trades relative to ADV. To make the implied capacity-ceiling reading auditable we evaluate the same data-derived headline with the create distribution reduced by a per-sample draw of the literature impact deduction at K-times current AUM, under two turnover-rolloff assumptions: turnover(K)=turnover(1)⋅K−α with α=0 (the worst case, in which annual portfolio turnover is held at its current ∼27× level as AUM grows) and α=0.35 (an industry-norm rolloff, which matches the empirical decreasing-returns-to-scale pattern documented for active managers in [56, 57, 70] and brings annual turnover to ∼5× by K=100×). The implied horizon Sharpe drag scales as K1/2−α, so the worst case grows as K and the industry-norm grows as K0.15.
Turnover trajectory
K=1×
K=10×
K=100×
Worst case (α=0, turnover frozen)
6.10
0.93
-2.01
Industry-norm rolloff (α=0.35)
6.05
4.59
2.90
Each cell is the headline t-RSI standardized distance under the same data-derived λdecay as the headline, with the create distribution reduced by the literature Q/ADV Sharpe drag at the indicated AUM scale and turnover trajectory. The K=1× column reports the literature counterfactual at current AUM (“what the literature law would predict if orders could not be split below the impact floor”); the firm’s realized t-RSI at the same operating point is 9.61 because orders are split below the floor and the empirical impact is sub-floor. The worst-case row crosses zero between K=10× and K=20× (the closed-form crossover is at K≈17×) and is decisively negative at K=100×; the industry-norm row compresses with K but remains positive across the full 100x range. Realistic capacity headroom sits between these two rows, anchored on the industry-norm trajectory.
Audit caveats.
The two t-RSI numbers a future reader will measure depend on how fast the create-side rows themselves move (sensors, actuators, parameters, R&D) and on operational choices the firm makes as AUM grows (universe expansion, execution-horizon extension, refit cadence). The headline reported here is the present standardized distance; the capacity-sensitivity table converts the same posterior into a forward-looking range under explicit, conservative-to-realistic turnover assumptions, but the cells will be re-measured against future data.
▸AppendixChannel Derivations
Channel Derivations
Investments Supporting Equations
The investment row’s auxiliary object is the learned execution-friction surface ϕt. It evaluates the per-trade friction as a function of the candidate trade ΔIt, the actuator surface Ut, and the market state Et. The overbraces below mark which input is which.
Backtest scope and friction surface.
The execution-friction surface ϕ that enters Investment marginal return via ϕt is, by construction, a function of the trade: half-spread, square-root impact, fees, financing, and adversarial response are all functions of (ΔIt,Ut,Et) paid at the moment of execution. This is what distinguishes ϕ from the time-rate alpha-decay term αdecay, which is a function of (Θt,Et,t) and lives outside the market function [39, 38, 40]. The two boxes are orthogonal in their dependencies, which is what makes them clean named primitives.
Realized cash on a single cycle is gross value minus frictions:
Yt$=i∑(pi⋅qi)−Φ(q),
where the sum runs over fills i in the cycle (qi units at realized price pi) and Φ(q) is total execution friction. Φ decomposes into four measurable components [41, 42, 39, 43, 44, 45, 46]:
Market impact (ϕimpact). The dominant friction. The firm’s own orders move the price against it. A common heuristic is the square-root impact law [39], ϕimpact≈σq/Vdaily, where σ is daily volatility and Vdaily is average daily volume. Decades of empirical support across asset classes and market regimes [41, 42]. The true impact function is more complex than any closed form suggests: payment for order flow, internalization, and venue-specific rebate structures mean that for some instruments and order sizes the firm receives price improvement (the opposite of the square-root penalty); impact also varies with time of day, volatility regime, and the firm’s own historical order patterns.
Exchange, clearing, and regulatory fees (ϕfees). Proportional to volume. Exchange fees, clearing fees, SEC fee, TAF. Small relative to impact and near-deterministic; typically fractions of a basis point per share.
Financing and borrowing costs (ϕfinancing). Cost of shorting (borrow fees for locating shares), margin interest on leveraged positions, cost of carrying overnight. Scales with position size and holding period. For intraday strategies with no overnight exposure, this component is near zero.
Adversarial costs (ϕadversarial). At larger scales, the firm’s trading patterns become detectable by other market participants. Sophisticated competitors can front-run predictable order flow, engage in quote-stuffing, or trigger stop-losses—increasing realized impact beyond what the mechanical friction model predicts. At the firm’s current trading scale, this term is negligible; it becomes material at higher AUM. Formally, adversarial costs introduce a multi-agent dimension to the market function: the firm must model how other participants model it, and how their responses to its detected patterns feed back into the prices it receives.
Measurability.
Each component of Φ can be estimated from the firm’s historical execution data with a confidence interval. Market impact has decades of empirical literature [41, 39, 42], and the firm generates new calibration data on every trade. Exchange fees are published schedules. Financing costs are contractual rates. Adversarial costs are estimated from historical decomposition of realized versus predicted impact. Every friction term in Execution Friction Identity is observable, estimable, and comes with a known variance.
Backtest scope.
A public backtest can recover the μ and αdecay terms of Investment marginal return from a walk-forward, survivorship-free universe and a fixed cost model. It cannot recover ϕt at production fidelity. Any published Sharpe figure that does not separately disclose its assumed friction surface is implicitly assuming ϕ=ϕstatic, which is exactly the assumption the live trading record discriminates against.
Proprietary surface.
The firm has executed approximately $400M of trades; that volume is the data behind its internal ϕt surface. The internal estimates are demonstrably tighter than the public square-root-law approximation above (routing, venue-specific spreads, financing, and the time-of-day component of impact all enter), but the surface itself is held proprietary for exactly the reason Investment marginal return makes plain—ϕ is the term the rest of the world cannot buy. The blueprint therefore treats backtest-derived numbers as upper bounds on the deployable trading row, with the Mark I/II/III hyperparameter ledger (Deployment Parameters) as the dated operator-side audit trail.
ϕt=ϕt(ΔIt,Ut,Et)
Sensors Supporting Equations
What this section does.
This subsection states the full model/data/architecture scaling surface, then shows the fixed-model, fixed-architecture specialization that the sensor row actually fits. It names every coefficient that enters the fitted slice, gives the fitting protocol that produces the numbers consumed by the body, and derives the local slope identity the chain rule actually calls. It is meant to be read on its own: a reader who only opens this appendix should leave with enough to reproduce the fitted numbers and to know what each one means.
Marginal return of the sensor channel.
The body’s sensor row consumes a single derivative off this fit: the local data-scaling slope ∂Lpred/∂log10Deff. Differentiating the scaling law term by term gives the body identity, which says the slope at any operating point is fixed by the product of the data-scaling exponent and the reducible component of the loss. The appendix then expands that measured primitive into the controller-level chain rule:
gtS=∂atS∂Deff⋅∂Deff∂Lpred⋅∂Lpred∂μ⋅∂μ∂Jt.
The remainder of this appendix defines each factor in that product (the full scaling surface and the slice the body fits, the fitting protocol, and the reported quantities) and closes with the transition law WtS that records how the next sensor inventory is distributed after a candidate sensor allocation, conditional on the sensor history.
The full surface and current slice.
The full scaling surface used by the code is the Kaplan/Hoffmann/Chinchilla model-size/data law with the Muennighoff repeated-data correction folded into Deff. In that surface, model size Mt and effective data Deff are scale axes, while architecture quality At moves the loss floor and scaling coefficients. The current multi-seed data-scaling sweep holds Mt=M0 and At=A0 fixed, so the model-size term and architecture dependence collapse into a one-dimensional fitted slice. The body reports that slice, not a completed cross-model-size scaling law.
The fitted sensor law.
On the fixed slice, the sensor row models per-asset predictive loss Lpred as a power law in an effective dollar-weighted-token axis Deff, plus a fixed-slice residual floor:
Lnoise is the fixed-(M0,A0) residual floor: the part of loss not reduced by buying more data while Mt and At are held fixed. It equals L∞(A0) plus the fixed-model architectural residual at the current (M0,A0), and true Bayes risk is its lower bound (reached only in the joint limit as Mt and At are simultaneously optimized). R&D moves At and therefore moves this floor; the body’s Lnoise row is read at the operating At, not at A⋆.
ADeff is the prefactor on the reducible part, in the same loss units as Lpred.
αDeff is the power-law exponent: each decade of Deff multiplies the reducible part by 10−αDeff.
Deff is the Muennighoff effective-data axis [47]: fresh dollar-weighted tokens UD plus repeated tokens deflated by an epoch-saturation constant R⋆.
UD is the count of fresh dollar-weighted tokens (single-pass dollar volume seen by training). The unit is the dollar-weighted bar [49, 50, 51].
E inside the Deff form is the number of training epochs actually run; R⋆ controls how quickly repeated passes deflate.
The equations below state the full surface, the fixed-slice law, and the Deff construction [9, 30].
Fitting protocol.
The four coefficients (αDeff,ADeff,Lnoise,R⋆) are recovered by a hierarchical Bayesian posterior over the 45 training-run panel, sampled with NUTS (4 chains ×2000 draws after warmup; max R=1, min ESS-bulk =1956.0). The likelihood is Gaussian on log-loss residuals: log10Lobs∼N(log10Lpred,σy). Two of the four coefficients are placed under informative priors that fold in external measurements:
R⋆∼N(4.28,1) epochs, with the prior center and width fixed by an independent epoch-saturation sweep.
Lnoise∼N(0.034,0.01), with the prior derived from a separate noise-floor decomposition that estimates the fixed-(M0,A0) residual floor from cross-asset residuals at the current operating architecture. True Bayes risk is a sub-component (lower bound) of this estimate, not the estimate itself.
The pin is not a stylistic choice: Lnoise and R⋆ are jointly only weakly identifiable from the 45-row (Deff,L) panel by itself, so an unconstrained fit lands on whichever corner of the joint surface minimises a particular residual without measuring an underlying quantity. The two informative priors carry the external information that does identify them. The remaining coefficients αDeff and log10ADeff are placed under weakly-informative priors (αDeff∼HalfNormal(0.5), log10ADeff∼N(0,2)) and identified from the data.
Reported quantities.
The §5.3 fitted-parameters table consumes the marginal posterior summaries directly: every value is the posterior mean of the corresponding marginal, every 95% CI is the marginal HPDI. The ADeff row is exponentiated from the log10ADeff marginal so the row reads in raw loss units; the HPDI bounds are exponentiated through the same transform. The headline numbers at the current operating point are αDeff=0.156 (HPDI [0.09,0.229]), ADeff=3.266 (HPDI [0.8072,16.87]), Lnoise=0.042 (HPDI [0.024,0.061]), and R⋆=4.306 epochs (HPDI [2.324,6.231], narrower than the prior because the data does pin R⋆ once Lnoise is anchored). The R2 column in the body table is a Bayes-R2 in raw-loss space, evaluated at the posterior means against the same 45 training runs, currently 0.7619. The 95% band on the §5.3 chart is the posterior-predictive envelope across thinned draws from the same posterior.
Transition law.
The transition law that follows the chain-rule statement above is the sensor-channel fragment of the learned EWM, WtS: it records how the next sensor inventory is distributed after a candidate sensor allocation, conditional on the sensor history.
The sensor marginal returngtS is the optimizer-level expansion of the local data-scaling slope used in the body. It chains sensor dollars → effective data Deff→ predictive loss Lpred→ expected return μ→ objective Jt; only the Deff→Lpred factor is measured in the sensors section itself.
gtS=∂atS∂Deff∂μ∂Jt∂Deff∂Lpred∂Lpred∂μ
Example
Suppose the firm spends atS=$50K on an options-flow archive that adds ΔUD$ fresh dollar-weighted tokens. ∂Deff/∂atS converts dollars into the Muennighoff axis, the fitted ∂Lpred/∂Deff moves predictive loss down along the multi-seed scaling slope of Local data-scaling slope, ∂μ/∂Lpred translates loss into expected return through the actuator panel, and ∂Jt/∂μ closes onto the cumulative objective. Only the middle factor is measured in this section; the two outer factors enter from the sensors-to-data conversion and the actuator slope respectively.
The sensor channel transition law is the sensor-channel fragment of the learned EWM, WtS. It returns the distribution over the next-cycle sensor inventory St+1 given the sensor history HtS and the sensor allocation atS the controller commits this cycle. The fitted data-scaling surface of Full Scaling Surface is the empirical content of this transition: it says how much effective dollar-weighted data atS buys and how that increment moves predictive loss.
St+1=WS(St,atS,Et)
Example
Suppose the firm commits atS=$50K to extend its options-flow archive by three years. Conditioning on the sensor history of past purchases, WtS returns a distribution over St+1 whose dollar-weighted-token mass on options-flow rises by the implied ΔUD$, with the predictive-loss reduction on the next refit drawn from the fitted Muennighoff surface.
Actuators Supporting Equations
What this section does.
This subsection explains the local data-performance slopes plotted in §5.4: realized annualized return and realized annualized Sharpe per decade of effective dollar-weighted data. In the general ontology, actuators are the interfaces through which the controller can act. In this empirical trading-envelope instance, the actuator surface is narrower: the tradable asset universe. Because the asset universe and the dollar-weighted data universe expand together in this sweep, the body reports the direct panel slopes and leaves the joint-path interpretation here.
Marginal return of the actuator channel.
The body’s actuator row consumes the two local data-performance slopes plotted in §5.4. The controller’s general actuator row is gtU (Actuator marginal return): actuator dollars move the capability surface Ut, that surface changes the learned execution-friction surface ϕt(ΔIt,Ut,Et) inside the investment production function, and the changed friction surface changes realized return. The current chart is one trading-envelope instance of that row, where Ut is the tradable asset universe and not a general claim about LLM APIs, robotics, or human labor. The remainder of this appendix defines the path along which Deff and Ut co-move, gives the OLS fitting protocol that produces the two body slopes, and closes with the capability-surface transition law WtU.
The local data-performance slopes.
Let N index the tradable universe size. The experiment moves along the path
Deff=Deff(N),Ut=Uttrade(N),
so the body slopes are total slopes along that path:
dlog10Deff(N)dμtann(Deff(N),Uttrade(N)),dlog10Deff(N)dSharpet(Deff(N),Uttrade(N)).
They can be interpreted as a data-to-loss term plus a tradable-surface term, but the body does not separately identify those two effects:
dlog10DeffdYt=∂Lpred∂Yt∂log10Deff∂Lpred+∂Uttrade∂Ytdlog10DeffdUttrade,Yt∈{μtann,Sharpet}.
The intermediate loss and realized-performance ranges are much narrower than the data range, so the directly measured panel slope is the stable body primitive.
Fitting protocol.
The two slopes (annualized return and annualized Sharpe) are recovered by ordinary least squares of the cluster-median realized metric on log10Deff:
Underlying panel. The asset-universe sweep contains 15 universe sizes × 3 seeds =45 raw runs. After joining the effective-data coordinate Deff=UD+UDR⋆(1−e−(E−1)/R⋆) to realized annualized return and Sharpe, the executable-coverage restriction leaves a 36-row (N,seed) panel.
Cluster medians. For each universe size N we take the median across the three seeds of (annualized return, Sharpe). We drop the three smallest universe sizes for which the per-seed median has insufficient evaluation breadth, leaving n=12 cluster-median rows. The body’s parameter table reports this n=12 as the regression’s degrees-of-freedom unit.
OLS. The slope and intercept come from a linear fit on (log10Deff(N),y(N)) across the 12 medians, separately for y=ann. return and y=Sharpe. The standard errors use the usual OLS residual variance σ2=SSE/(n−2) and prediction variance SEy^(x)2=σ2(1+1/n+(log10x−log10x)2/Sxx).
Cluster-by-N bootstrap. The 36-row (N,seed) panel is the object the cluster-by-N bootstrap of Three-Month t-RSI Calculation resamples for the t-RSI numerator’s seed-noise leg.
Why OLS, not Bayesian.
The sensor row uses a hierarchical Bayesian posterior because Lnoise and R⋆ are jointly only weakly identifiable from the (Deff,L) panel and require informative priors derived from independent measurements (see Sensors Supporting Equations). The actuator row is a different problem: a single linear fit through 12 cluster medians where the slope and intercept are jointly identified by elementary OLS algebra. There is no analogous degeneracy and no external information that needs to be folded in via priors, so OLS prediction intervals are well-calibrated and we use them directly.
Chart construction.
The §5.4 chart shows, for each of the two metrics:
Per-N cluster median (filled dot, n=12) and seed min/max as vertical error bars.
OLS log-x fit line y=β^log10Deff+α^, with R2 printed in the legend.
Parametric 95% prediction-interval band (filled region) on the same σ2(1+1/n+…) formula above.
TA and TB vertical dashed marks at Deff(TA)=Dop⋅102.31 and Deff(TB)=Dop⋅103.71, where Dop=maxNDeff(N) is the operating point of the current sweep. The headroom dex match the sensor headline chart in §5.3 so the two charts share an x-axis interpretation.
Extrapolated TA, TB markers with vertical 95% PI error bars: these are the same y^(TA) and y^(TB) values reported in the §5.4 fitted-parameters table.
The chart has no R2 annotation per tier marker because R2 is a property of the regression that produced the slope, not of any single derived point. The body table reports R2 on the slope rows and leaves the TA/TB extrapolation rows blank in the R2 column for the same reason.
Reported quantities.
The §5.4 fitted-parameters table consumes the OLS bookkeeping directly. The slope rows give the local return-data and Sharpe-data slopes plus 95% CIs from β^±1.96⋅SEβ^ and the regression R2. The four extrapolation rows — AnnRet(TA), AnnRet(TB), Sharpe(TA), Sharpe(TB) — give the OLS prediction mean and the parametric 95% prediction interval evaluated at log10Deff(TA) and log10Deff(TB).
Capability surface and transition.
In this section’s local trading instance, the actuator state is the tradable asset universe (Actuator Capability Surface). The transition law WtU (Actuator channel transition law) describes how that surface evolves with actuator spend and the environment.
Ut=UtvenuesUtLLM-APIUtroboticsUthumans
Definition 36Actuator marginal return
The actuator marginal returngtU chains actuator dollars → capability surface Ut→ learned friction ϕt→ realized return. Buying an actuator is buying capacity in the friction surface that converts the controller’s intended trade into realized cash.
Suppose AlphaFund adds an IEX D-Limit route that cuts the venue-selection contribution to ϕt by 0.4 bps per dollar traded. On a $120M deployed book turning over ∼30% per cycle, that is $120M×0.30×0.00004≈$1,440 per cycle of recovered alpha; gtU prices this against the cycle cost of the connection.
Definition 37Actuator channel transition law
The actuator channel transition lawWtU returns the distribution over the next-cycle actuator surface Ut+1 given the actuator history HtU and the actuator allocation atU. In the trading-envelope instance the actuator surface is the tradable asset universe of Actuator Capability Surface, and the empirical content of this transition is the OLS panel slope in Local data-performance slopes: how much realized Sharpe a decade of additional dollar-weighted tokens buys when the universe widens along the firm’s deployment path.
Ut+1=WU(Ut,atU,Et)
Example
Suppose the firm commits atU=$120K to widen its tradable universe from 127 to 160 assets (new venue access, additional brokerage agreements, the engineering work to support the larger asset universe). Conditioning on the actuator history, WtU returns a distribution over Ut+1 that contains the 33 additional names, and the OLS panel slope of Local data-performance slopes prices the implied gain in deployed Sharpe per decade of dollar-weighted tokens absorbed across the widened universe.
R&D Supporting Equations
What this section does.
This subsection states the empirical R&D primitive plotted in §5.5 — the selected rolling upper-tail held-out frontier of the auto-research campaign as a function of completed experiments — and gives enough fitting protocol that a reader who only opens this appendix can reproduce the reported numbers and locate the derivatives inside the controller chain rule. The structural stack underneath the body derivative (dollars → experiments → architecture-quality scalar Γt→ coefficient vector η(Γt)→ predictive loss) is included for completeness; the body keeps only the two measured derivatives.
Marginal return of the R&D channel.
The body’s R&D row consumes a single derivative off each selected frontier fit: the local derivative of the report-selected top-10% held-out Sharpe frontier with respect to log-experiments, ∂Sharpe/∂log10(1+n) at the current ncurrentexp, with the analogous top-10% derivative for annualized return. The appendix then expands that measured primitive into the controller-level chain rule of R\&D marginal return: dollars → experiments through the dollar-to-experiment production function, experiments → architecture quality through the search-scaling law, architecture quality → scaling-surface coefficients through the architecture-coefficient map, scaling coefficients → predictive loss through the joint surface, and predictive loss → expected return through the actuator slope. The R&D row is therefore the only channel-row whose body derivative and structural derivative are not the same object: the body derivative is a faithful downstream readout of the firm’s actually-optimized metrics, and the structural derivative on Γt remains queued behind the per-architecture coefficient sweep referenced below. The remainder of this appendix defines each factor in that chain rule (the full stack, the fitted law, task-based automation, fitting protocol, chart construction, reported quantities) and closes with the R&D EWM transition law WtZ.
The full stack and the slice the body uses.
R&D dollars decompose into human-researcher and LLM/agent dollar streams (Rnd Allocation Split). The dollar-to-experiment production function (Rnd Experiment Throughput) converts those streams into completed-experiment count via per-arm productivity rates ρthuman and ρtLLM (experiments per dollar). The search-scaling law (Search Scaling Law) maps completed experiments to the dimensionless architecture-quality index Γt, and the architecture-coefficient map (Architecture Coefficient Map) records which coefficients of the joint Kaplan/Hoffmann/Chinchilla/Muennighoff scaling surface are moved by Γt. The transition law WtZ records how the R&D state evolves between cycles. The body’s §5.5 derivatives ∂Sharpe/∂log10(1+n) and ∂AnnReturn/∂log10(1+n) are downstream-projection derivatives against the metrics the firm optimizes against (validation Sharpe and validation annualized return), not structural derivatives against Γt; the structural slope ξΓ requires a per-architecture coefficient sweep that fits η(Γ) jointly across architectures and is the natural extension of the multi-seed sensor sweep along the Γ axis.
The fitted R&D law.
On the strict-invalid- and sealed-holdout-filtered cohort, rolling upper-tail frontiers of validation Sharpe and validation annualized return are each modelled as a logarithmic experiments-performance law in the completed-experiment index n:
n is the experiment index after sorting the filtered cohort by run identifier; the upper-tail frontier is the rolling mean of the best observed scores so far at the selected cutoff.
β0,Sharpe and β0,AnnReturn are the level intercepts at n=0 in Sharpe and percentage points respectively.
∂Sharpe/∂log10(1+n) and ∂AnnReturn/∂log10(1+n) are the derivatives the body table reports, in Sharpe per unit of log10(1+n) and percentage points per unit of log10(1+n) respectively. At the operating cohort size (n≫1) one unit of log10(1+n) is, to within log10(1+1/n), a ten-fold increase in completed experiments, so the derivative reads naturally as “per decade of experiments”; we use that shorthand in the body table and figure labels, with the exact units stated here.
ncurrentexp is the cohort size after filtering — the count of experiments the firm has actually completed and the warm-start point for the local marginal calculation.
The task-based automation term (Task Based Automation) defines ftauto=ρtLLM/ρthuman as the integral over the research task set T of per-task automation feasibility pauto(σ,t) weighted by human-researcher cost whuman(σ), normalized by total human-research cost. The functional form mirrors the task-automation literature [71, 72, 73], in which capital substitutes for human labor on a measurable subset of the task distribution rather than uniformly across it. Empirically the ratio has two external anchors: its level at time t comes from the Anthropic Economic Index / AIoE task-exposure dataset cross-walked through ONET against the firm’s own task list, and its time-derivative is anchored by the METR autonomous-task-horizon doubling time τ2×≈7 months [53]. Holding ρthuman slowly varying over the relevant horizon, ρtLLM grows on the same schedule, and the cost-equivalent LLM share of completed experiments rises proportionately. The optimizer chooses the human/LLM mix endogenously through the budget constraint atZ=atZ,human+atZ,LLM; the firm currently sits near the LLM endpoint of the substitution path because that is where ρtLLMatZ,LLM is largest at the present operating budget, and the 929-experiment headline campaign is one realized draw of that endpoint.
Team-size diminishing returns.
Pure-human research throughput does not scale linearly in headcount: communication overhead grows with team size NH and erodes the marginal productivity of each additional hire, the Brooks coordination-drag effect [74]. The clean way to absorb this is to let ρthuman depend on NH rather than introducing a separate parametric form for the human arm. The firm has not yet run a controlled headcount-vs-output study on its own R&D history, so this dependency remains a structural placeholder; the corresponding parameters are not reported as fitted values in the body table.
Fitting protocol.
The filtered cohort starts from the 929-experiment auto-research clean table and applies two measurement-quality exclusions: the curated removal flag (rows the campaign audit marked as buggy, contaminated-holdout, look-ahead, or carrying an invalid-metric marker) and a single-evaluator implausibility flag (validation Calmar >2.05, validation Sortino >2.50, or validation Sharpe >1.90 on the surviving rows); sealed-holdout rows are also dropped by name. Both exclusions are on measurement quality, not on outcome: the dropped runs are samples from the measurement-failure distribution, not the search-process distribution. Within the resulting cohort, rows are sorted by run identifier, the metric of interest is restricted to its finite-valued subset, and the experiment index n=1,2,… is assigned along that sorted sequence. Candidate frontiers are the rolling means of the best top-5%, top-10%, and top-20% observed scores so far. Each candidate frontier is fit against log10(1+n) by ordinary least squares and scored by rolling-origin prediction on held-out suffixes; the whitepaper manifest pins the body frontier to top-10% for both metrics, and the appendix reports the full cutoff scan. The same protocol is applied to validation annualized return, with the clean column rescaled by 100 inside the fit so the derivative reads in percentage points.
Chart construction.
The §5.5 evidence is split across two single-panel figures with a shared x-axis on completed experiments n: one for held-out Sharpe and one for held-out annualized return (in percentage points). Each figure carries the raw per-experiment scatter, the SPY baseline, the muted running-best step as context, the selected rolling upper-tail frontier, the bootstrap band around that selected frontier, and the fitted log law. The two fitted curves and the two derivative rows in the body table come from the same selected-frontier fits. The held-out trajectory is the canonical 1258-day validation window each run reports against the 2516-day training period; the same window applies to every chart in §5.5.
Reported quantities.
The §5.5 fitted-parameters table consumes the selected frontier fits directly. The two intercept rows β0,Sharpe and β0,AnnReturn give the level of the selected frontier curve at n=0; the two derivative rows give the per-decade gain on that frontier. The 95% confidence intervals are bootstrap percentile intervals from resampling experiments with replacement, recomputing the selected frontier, and refitting the log law; the R2 column reports the regression’s fit to the selected upper-tail curve and the n column reports the cohort size after filtering.
Transition law.
The R&D EWM transition WtZ (R\&D channel transition law) records how the next R&D capability state is distributed after a candidate allocation, conditional on the R&D history. The empirical anchor is the same auto-research campaign: at the deployed human/LLM mix, each cycle’s allocation generates a draw from the campaign’s per-experiment performance distribution, and the selected upper-tail frontier summarizes the improving opportunity set across cycles. The body derivatives summarize how that selected frontier has evolved with n on the observed campaign.
The R&D marginal returngtZ chains R&D dollars → completed experiments Ntexp (human plus LLM/agent throughput at per-arm productivity rates ρthuman, ρtLLM) → architecture quality Γt→ Hoffmann/Chinchilla coefficient vector η(Γt)→ predictive loss → expected return. R&D acts on the shape of the scaling surface itself, not on its current operating point.
AlphaFund’s 929-experiment auto-research campaign, restricted to the strict-invalid- and sealed-holdout-filtered cohort, fits selected rolling upper-tail frontiers for validation Sharpe and validation annualized return. The body uses the report-selected top-10% frontier for both metrics. Suppose the firm completes ten times as many experiments at its current automation rate: the selected validation-Sharpe frontier is projected to gain about ∂Sharpe/∂log10(1+n) Sharpe, and the selected annualized-return frontier is projected to gain about ∂AnnReturn/∂log10(1+n) percentage points, evaluated as the local increment of the fitted curve from the current campaign count. These derivatives then propagate through the architecture-coefficient map η(Γt) to the loss surface and the expected return inside the trajectory chain rule (Channel Derivations).
Definition 39R\&D channel transition law
The R&D channel transition lawWtZ returns the distribution over the next-cycle R&D capability state Zt+1 given the R&D history HtZ and the R&D allocation atZ. The empirical content is the auto-research campaign of Experiments-performance slope: at the deployed human/LLM mix, each cycle’s allocation generates a draw from the campaign’s per-experiment performance distribution, and the selected upper-tail frontier summarizes how the improving opportunity set evolves with n.
Zt+1=WR(Zt,atZ,Ht)
Example
Suppose the controller commits atZ=$400K to a quarter of R&D, split $100K human and $300K LLM/agent under the current ρtLLM/ρthuman ratio. Conditioning on the auto-research history, WtZ returns a distribution over the next R&D state in which the realized experiment count Ntexp is drawn from Rnd Experiment Throughput and the top-10% Sharpe frontier shifts by the local ∂Sharpe/∂log10(1+n) derivative of Experiments-performance slope.
Parameters Supporting Equations
The parameters channel rests on the full Kaplan/Hoffmann/Chinchilla/Muennighoff loss surface [30, 9, 47]: an architecture-set loss floor, a model-size term, and an effective-data term whose data axis already deflates repeated epochs. The current sensor fit fixes Mt=M0 and At=A0; the model-size sweep needed to identify αM(At) and AM(At) remains a future fit. The compute-cost identity (training FLOPs equals tokens times passes times model size, divided by training efficiency) states which (Mt,Dt,Kt) choices are feasible, and the transition law states how weights move between cycles.
The parameters channel transition lawWtΘ returns the distribution over the next-cycle weight vector Θt+1 given the parameter history HtΘ and the parameter allocation atΘ (training compute purchased this cycle). The empirical content is the joint Kaplan/Hoffmann/Chinchilla/Muennighoff scaling surface of Parameters Joint Scaling: the next weight set is the optimizer’s output after consuming atΘ worth of compute on the current Deff corpus, with its held-out predictive loss drawn from the fitted surface.
Θt+1=WΘ(Θt,atΘ,St,Cttrain)
Example
Suppose the firm commits atΘ=$80K to one production refit on the current 863-asset corpus: ∼$80K of H200 hours produces a new Θt+1 at model size M0. Conditioning on the parameter history, WtΘ returns a distribution over Θt+1 whose realized predictive loss is drawn from the fitted surface at the current (M0,Deff,A0) operating point.
Continual Learning Supporting Equations
The continual-learning channel is the bridge between the static parameters channel (§ 5.6) and the live deployed model. The empirical content is the epoch-multiplier intersection chart in § 5.7: where the production LKaplanK⋆=3 frontier and the single-pass LKaplanK=1 frontier cross, the effective number of optimizer passes through the current-bar corpus that maximises validation loss reduction is identified. Per-cycle continual-learning alpha is the share of ΔαR&D and Δαdata+act that the refit cadence converts into deployed Sharpe at the intersection epoch; in the headline t-RSI calculation of Three-Month t-RSI Calculation this row is folded into sensors+actuators rather than separately identified, and a future revision will split it out once a multi-cadence retraining sweep delivers the refit-cost coefficient.
▸AppendixData Scaling
Data Scaling
Direct Versus Chained Fit
The body proves the realized-portfolio map two ways. The chained estimator composes the data-scaling fit Equation 56 with the loss-to-edge linearization measured in the actuator panel: data dollars buy effective-token volume Deff, Deff buys reducible predictive loss, and reducible loss buys realized edge μ. The direct estimator skips the data-side regression and fits μ as a function of Lpred on the same 45-run sweep (the loss-to-edge slope b measured directly from the realized portfolio data; cf. Figure 5). The chain composes only if the two paths recover one another within their joint uncertainty.
On the current 45-run multi-seed scaling sweep, a linear-in-log10Lpred regression on the per-(N,seed) points yields
each decade of reducible predictive loss converts to ∣6.4425∣ percentage points of annualized return and ∣0.3972∣ units of Sharpe. The chained estimator recovers the same slopes within one standard error on this dataset: pushed to the cross-asset loss endpoint LTB=0.03634 (95% PI [8.17233×10−6,0.03645]) from Equation 56, the loss-to-edge linearization projects approximately 44.2364% annualized return ([28.5026,59.9702]) and Sharpe approximately 2.5881 ([2.0491,3.1272]); these agree within one standard error with the chain-composed counterpart. Both extrapolations are upper bounds: alpha decay and execution friction at frontier dollar-volume scales will bend the realized curve below the in-sample slope.
Selection-Rule Efficient Frontier
A natural worry is that aggregating per-asset MAE over the entire training universe washes out a signal concentrated in the model’s high-confidence predictions, and that a top-K selection rule would recover a tighter scaling exponent. We test this empirically. For each
K∈{5,10,20,50,100,200,500,∞}
(where ∞ is no selection) we restrict the per-asset MAE to the top-K symbols per run on the headline channel (ranked by predicted-magnitude proxy ∣ft∣), aggregate to an neval-weighted MAE per run, and re-fit Equation 56 on the canonical Deff axis. Figure 6 reports α(K) on the left and the per-K loss-vs-Deff curves on the right. Aggressive top-K selection erases the data-scaling signal: at K≤50 the fitted exponent is small or negative because tightening the asset set primarily reduces the universe-size variation that drives the regression. The body fit therefore uses no selection, which is also the only choice that aligns with how the deployed allocator consumes the predictions.
Robustness: Jackknife, Cook's Distance, Leverage
The headline Hoffmann/Muennighoff fit Equation 56 is run on all 45 per-(N,seed) points across the 15 universe sizes. Two sensitivity checks bracket the headline number. The leave-one-universe-out jackknife refits the same form 45 times, dropping one point at a time, and yields an alpha range of
[0.0751,0.28237]
around the headline α=0.07517 – a width comparable to one standard error and well inside the confidence the body needs to commit reinvestment on the sensor channel. On the log-log linear analogue used to construct the 95% prediction interval the smallest universes carry the highest leverage, as expected for an axis with approximately 3.5 OOM in-sample range, and the jackknife range above already shows that no single point dominates the fit. The 95% prediction interval at the cross-asset endpoint
Deff=4.046×1017
is
[8.17233×10−6,0.03645]
around the central estimate 0.03634.
What the Chart Says and Extrapolation Robustness
To read the headline chart of §5.3 (see Data Scaling) correctly: the x-axis is the volume of effective dollar-weighted tokens the model has trained on, not the count of distinct predictive factors or signals engineered into the feature set. The takeaway is not “each new factor adds this much edge”; it is that buying more dollar-weighted bars—raw measurement volume of the same kind the model already consumes—reduces predictive loss at a measured power-law rate, and that realistic procurement and sampling paths scale that volume by one to several orders of magnitude beyond the current operating point. The model/architecture surface that the fixed-slice fit specializes is given in Sensors Supporting Equations; the direct-versus-chained, selection-rule, and jackknife/Cook’s-distance checks in the preceding subsections of this appendix are the robustness backbone for that extrapolation.
If αDeff holds across the next decade of effective dollar-weighted tokens—a modest extrapolation against the operating point, with the realistic procurement and sampling factors cataloged here—then the reducible part of predictive loss falls by about 30% (HPDI roughly [19%,41%], propagated from the αDeff HPDI [0.09,0.229]), and the same multiplier compounds approximately decade-on-decade so long as the slope persists and the operating point stays inside the fitted regime. Power-law data-scaling of this Kaplan/Hoffmann form is one of the most robust empirical regularities in modern machine learning, having now been reproduced across many orders of magnitude in language [30, 9, 47], images [75], video and other generative modalities [76], mixed-modal models [77], geospatial foundation models [78], time-series foundation models [79], and protein biology [80]; recovering the same shape on the dollar-weighted-bar axis is consistent with that body of evidence rather than an exotic claim.
▸AppendixDeployment Parameters
Deployment Parameters
This appendix collects the per-generation hyperparameters across the three deployment generations. Mark I and Mark II predate the current ASIC ledger; their numerical hyperparameters are reconstructed from operator memory and the deployment diary, not from a re-runnable training manifest. The Mark II realized PnL, Sortino, and Sharpe are taken from the audited Luz Capital reproduction; the corresponding live AlphaFund-vs-SPY breakdown for Mark III is forwarded from the formal paper’s Appendix J and the live-trading reliability/capacity audit lives in the formal paper’s Appendix K.
Deployment hyperparameters across Mark I, Mark II, and Mark III. Pre-Mark III numbers are reconstructed from the deployment diary; the Mark II PnL, Sortino, and Sharpe come from the audited Luz Capital reproduction (referenced by the body table). The Mark III row is the deployment under which the live trading record is currently being accumulated; the formal paper’s Appendix J carries the per-account AlphaFund-vs-SPY breakdown.
Quantity
Mark I
Mark II
Mark III
Model class
long-only US equities
long/short US equities
long-only US equities
Model size
∼10M params
∼25M params
∼56M params
Training hardware
1×consumer GPU
4×A100
8×H100
Bar grain
daily
∼30-minute
∼1-hour
Universe
∼100 liquid US single-names
∼400 US single-names
∼500–800 US single-names
Cycle horizon
end-of-day rebalance
intraday + overnight
intraday + overnight
Window
∼8 months
10.5 months
Oct 21, 2025 – May 2026
Realized PnL
underperformed
+34.5%
+39% (formal paper App. J)
Sortino
<1.0
3.06
live
Sharpe
—
2.44
live
Beta to SPY
—
∼0.4
live
Turnover (per cycle)
∼3×
∼10×
live
Cause of transition
retired (bid–ask spread mis-modelling)
regime-shift detection (Aug 2024)
live (operator-managed)
Mark III is AlphaFund’s currently live deployment: it went live on October 21, 2025 and is trading continuously as of this writing.
What’s in μt and ϕt.
The headline edge μt in Investment marginal return is the Mark III EWM’s per-trade forecast conditional on the current book and filtration. The friction surface ϕt aggregates the four components catalogued in Investments Supporting Equations — impact, exchange/clearing/regulatory fees, financing, and adversarial response — into a per-trade scalar drag. Both are estimated against the ∼$400M of executed trades the Mark III deployment has cleared; the resulting numerical surfaces are proprietary, in line with the redacted rows of the investments parameter table.
▸AppendixImprovement Certificate
Improvement Certificate
Certificate of Monotone Improvement
Definition 41Certificate of monotone improvement
The certificate of monotone improvement is the thresholded form of the held-out t-RSI statistic that gates each capital commit. Certt=1 when, for every active channel c, the local Fisher information of the EWM I(c,Wt) has reached its evaluator-specific readiness floor εcand the held-out horizon t-RSI clears the Sharpe-margin threshold ζ=δ/Ut. The certificate fires channel-by-channel because the proper-scoring rule of Empirical EWM estimator accumulates evidence per channel history; it ratchets the corporate loop because every fired commit adds a new row that tightens both the EWM posterior and the t-RSI denominator on subsequent cycles.
Certt=1(∀c∈active(I(c,Wt)≥εc∧t-RSI(t,H)≥ζ))
Example
Suppose a candidate Mark III refit arrives at cycle t. The sensors row’s Fisher information I(S,Wt) has cleared εS (the multi-seed scaling sweep is identified), and so have the actuators and parameters rows. The held-out three-month t-RSI from Three-Month t-RSI Calculation stands at 1.45 against a margin threshold ζ=1.0. Both clauses hold, so Certt=1 and the controller commits the refit. If the refit had instead pushed t-RSI to 0.6, the second clause would fail and the controller would reject the commit.